Something about GAN
Contents
最近在看关于GANs的论文,并且自己动手用PyTorch写了一些经典文章的实现,想要稍微总结一下,故有此文。在最后我总结了我自己看过的有关GANs的一些比较好的资源,希望对读者有所帮助。
Before Reading: PyTorch
在讲GANs之前,首先推一波PyTorch。就我的使用体验来说,PyTorch是远远超过TensorFlow的。PyTorch作为一个动态图计算的框架,与Python结合得非常好,写出来的代码非常*Pythonic*(反例就是TF的tf.while_loop)。同时PyTorch与NumPy结合得非常好,不用在Tensor与ndarray之间转换来转换去。
总而言之,PyTorch非常适合我这样需要快速开发与快速验证,并且对于运行速度要求并不高的DL研究(讲真,TF的速度也不怎么快,还是吃内存大户)。
Introduction
GANs(Generative Adversarial Networks,生成对抗网络)是Generative Models(生成模型)的一种。所谓生成模型,就是能在一个含有真实数据分布$p_{data}$样本(samples)的训练集上,学习到真实数据分布的估计的表示$p_{model}$的模型。学习到的这个表示可以是显式的(explicit),比如说直接就给出了$p_{model}$;也可以是隐式的(implicit),比如说能够生成符合$p_{model}$分布的样本。一般来说,GANs属于第二种,能够进行样本生成。不过在设计上,GANs其实是两者皆可的。
那为什么要搞这个生成模型呢?原因也是有很多的。比如说,训练生成样本是一个用来测试我们表示高维概率分布的能力的好方法,而现实世界的物体往往是具有高维概率分布的,这就对我们用DL来表示与解释现实世界有帮助。同时,很多DL相关的任务也是很需要样本生成的,比如说超分辨率(super resolution)、风格迁移(style transfer)之类的。此外,生成模型对于某些标签甚至是数据缺失的数据集也很有用,比如说可以用在半监督学习(semi-supervised learning)上,不过我倒是没见到过相关的论文。总之,生成模型是很有用的,也是目前DL领域的一大热门方向。
那么问题又来了,还有哪些生成模型,GANs相比于其他的生成模型有什么优势,特别是在去年和它几乎同时火起来的VAE?首先谈谈生成模型的分类。说起这个,就不得不谈极大似然估计(maximum likelihood estimation),几乎所有的生成模型都使用了或者可以转换为使用极大似然来进行估计。极大似然估计的基本思想是,定义一个含有参数$\theta$的模型,用它来提供对于一个概率分布的估计,然后寻找一组最优的参数$\theta$来使得模型的概率分布$p_{model}$最贴合实际数据的概率分布$p_{data}$。具体地说,对于一个具有$m$个样本$x^{(i)}$的数据集来说,可以用似然(likelihood)来表示模型与数据集中数据的契合概率$\prod^m_{i=1} p_{model} (x^{(i)};\theta)$,而我们的最终目的就是找到使得似然最大的参数$\theta$。由于对数函数的优良性质,我们可以将似然取对数。
$$
\begin{align}
\theta ^* &= \underset{\theta}{\operatorname{argmax}} \prod ^m _{i=1} p_{model} (x^{(i)};\theta) \
&= \underset{\theta}{\operatorname{argmax}} \log \prod ^m _{i=1} p_{model} (x^{(i)};\theta) \
&= \underset{\theta}{\operatorname{argmax}} \sum ^m _{i=1} \log p_{model} (x^{(i)};\theta) \
\end{align}
$$
另外一方面,我们也可以将极大似然估计看成是一种最小化真实概率分布与模型概率分布之间的KL散度(Kullback–Leibler divergence)的方法。虽然我们通常在实践中并不能直接接触到$p_{data}$,而是只能够获得服从其分布的$m$个采样。我们可以用这些采样组成的数据集来定义$\hat{p} _{data}$这么一个经验分布(empirical distribution)来近似$p_{data}$。可以证明,最小化$\hat{p} _{data}$与$p _{model}$之间的KL散度,等价于在数据集上最大化对数似然。 $$ \theta ^*= \underset{\theta}{\operatorname{argmin}} D_{KL} (p_{data} (x) \parallel p_{model} (x;\theta)) $$
好了,说了这么多,让我们再把话题转向生成模型的分类。生成模型可以根据其计算似然及其梯度,或者近似估计这些值的方法来进行分类。其中值得注意的有FBVNs、VAE以及GANs。GANs属于右边的那一类,能够隐式地得到概率密度,并直接从中生成样本。
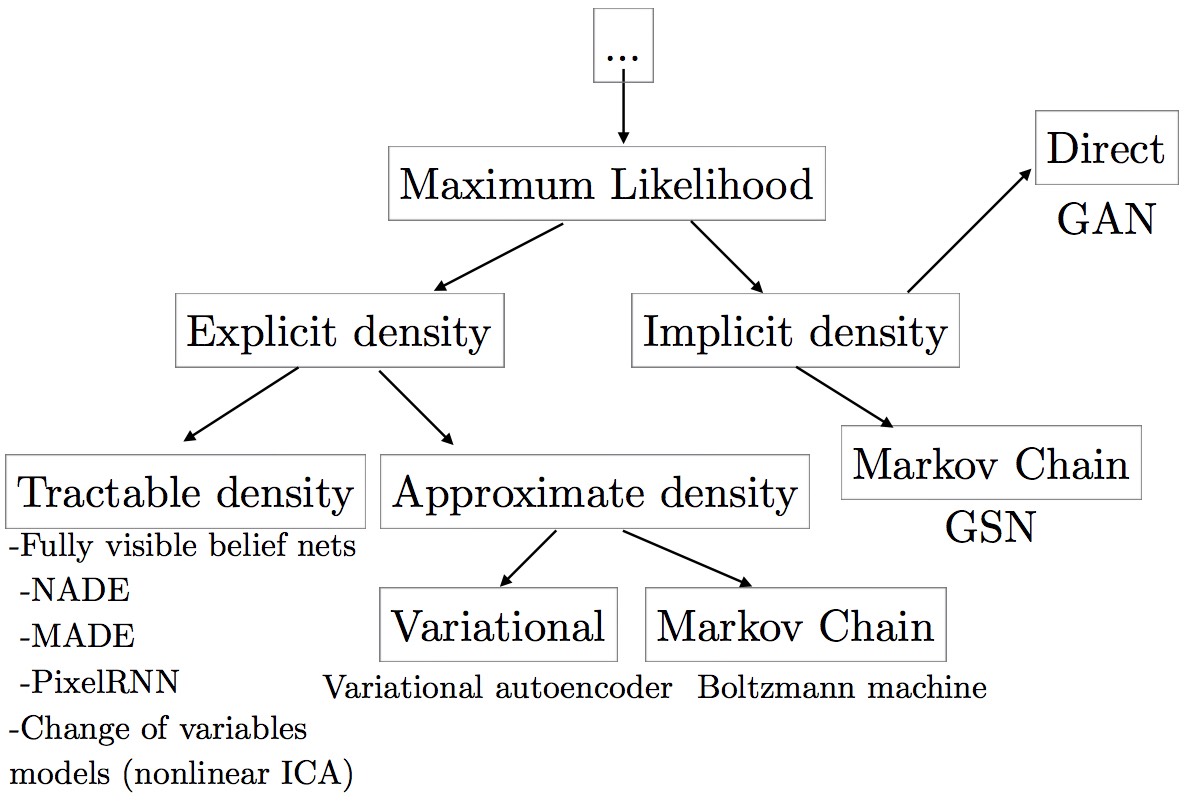
GANs相对于其他的生成模型,其优点主要在于:
- GANs能够并行地生成样本,而非FBVNs那样只能串行;
- GANs在设计上的约束很少,不像玻尔兹曼机(Boltzmann Machine)那样只能用少数几种概率分布,也不像非线性ICA那样,要求生成器必须可逆并且隐式编码(latent code)$z$必须与数据集中的样本$x$具有相同的维度;
- GANs不需要马尔科夫链(Markov chains),这点不同于玻尔兹曼机以及GSNs;
- GANs不需要使用微分边界(variational bound),并且GANs里面用到的模型早已被证明是万能逼近器(universial approximators),因此GANs能够保证渐进一致(asymptotically consistent)。相比而言,某些VAEs虽然推测是渐进一致的,但是没有得到证明;
- 最后一点,GANs就目前的效果来说,其生成出来的样本的质量比用其他生成模型得到的要好。
当然,原始的GANs有一点是非常让人头疼的,就是它的训练过程本质上是寻找一场比赛的纳什均衡(Nash equilibrium)的过程,这导致GANs很难稳定的训练。当然,之后要提到的WGAN在一定程度上解决了这问题。
How do GANs Work?
The GAN framework
GANs由两个部分组成:一个是生成器(generator),负责生成样本,并且尽力与原始数据集中的分布一致;另一个是判别器(discriminator),负责检验输入的样本是来自真实数据分布还是生成器生成的。这两者都可以表现为可微的函数(其实最后就是表现为神经网络),生成器是以$z$为输入,$\theta^{(G)}$为参数的函数$G$,而判别器是以$x$为输入,$\theta^{(D)}$为参数的函数$D$。生成器的目的是在只能控制$\theta^{(G)}$的情况下,最小化$J^{(G)} (\theta ^{(D)}, \theta ^{(G)})$;而判别器则是在只能改变$\theta^{(D)}$的情况下,最小化$J^{(D)} (\theta ^{(D)}, \theta ^{(G)})$。通俗地说就是,生成器想要生成出的样本能够让判别器区分不出这是来自真实数据还是生成的($D(G(z))=1$),而判别器则是想要尽可能地将这些区分开来($D(G(z))=0$)。这么一来,这场比赛的解就是一个纳什均衡。也就是说,这个解$(\theta ^{(D)}, \theta ^{(G)})$不但能在$J^{(G)}$上取到局部最小值(local minimum),而且在$J^{(D)}$上也取到局部最小值。如果两者均具有足够的容量(capacity),则$\forall x, D(x)=D(G(z))=\frac{1}{2}$。
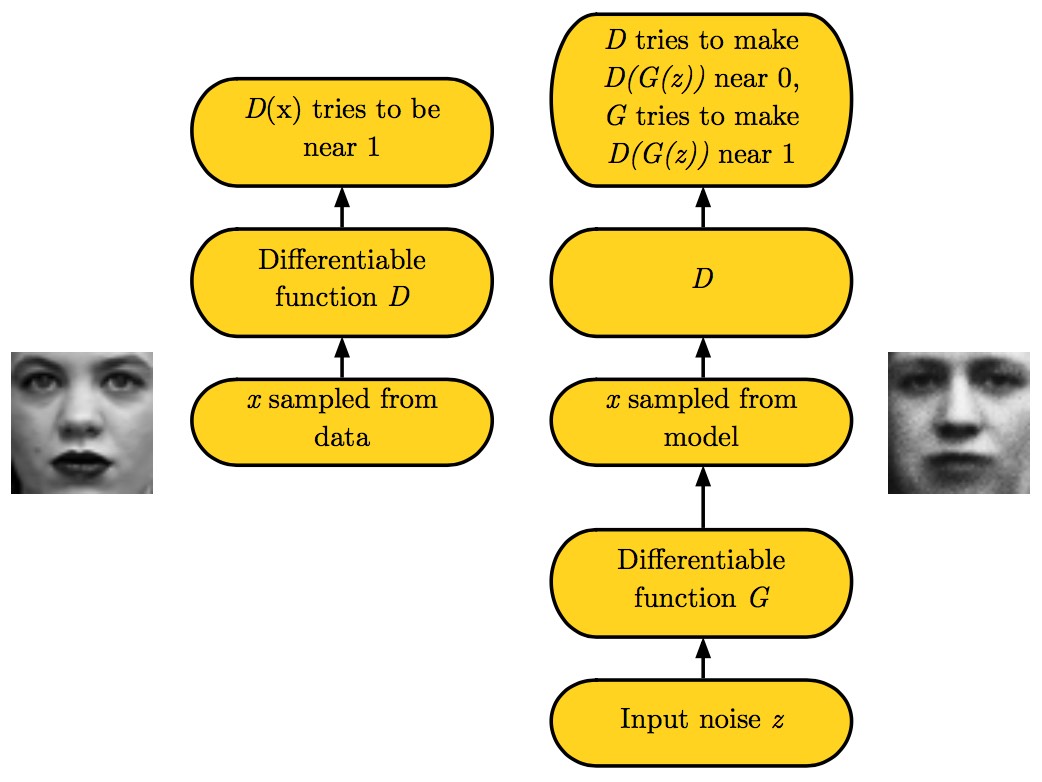
生成器就是一个简单的可微分的函数$G$,一般来说我们用DNN来表示。生成器接受一个来自先验分布(比如说高斯分布)的采样$z$,然后对其进行处理,得到一个来自$p_{model}$分布的采样$G(z)$。值得注意的是,我们并不一定要把$z$作为DNN第一层的输入。比如说我们可以把$z$一刀切成两部分,$z^{(1)}$和$z^{(2)}$,$z^{(1)}$作为DNN首层的输入,而$z^{(2)}$则加在DNN末层的输出上。还有一种操作是,我们可以在DNN的隐藏层上搞加性噪声(additive noise)或者乘性噪声(multiplicative noise),或者直接在隐藏层输出上串(concatenate)一个噪声。总而言之,生成器网络在设计上的约束是很少的,可以任意开脑洞,只要保证$z$的维度不低于$x$,并且整个网络是可微的就可以了。
判别器就是一个简单的二分类的DNN,在此就不赘述了。
Cost function
判别器的代价函数就是简单的交叉熵(cross-entropy cost),如下所示。唯一的区别是,判别器的一次训练由两个mini-batches组成,一部分是来自于数据集的真实样本,标签为1;另一部分是来自生成器所生成的样本,标签为0。一般来说,所有的GANs的判别器都是用下述公式作为代价函数的。 $$ J^{(D)} (\theta ^{(D)}, \theta ^{(G)}) = -\frac{1}{2} \mathbb{E}_{x\sim p_{data}} \log D(x) - \frac{1}{2} \mathbb{E}_{z} \log (1-D(G(z))) $$ 生成器的代价函数的可选择范围就稍微多了一些,主要有minimax、heuristic以及maximum likelihood三种,其中前两种比较常见。
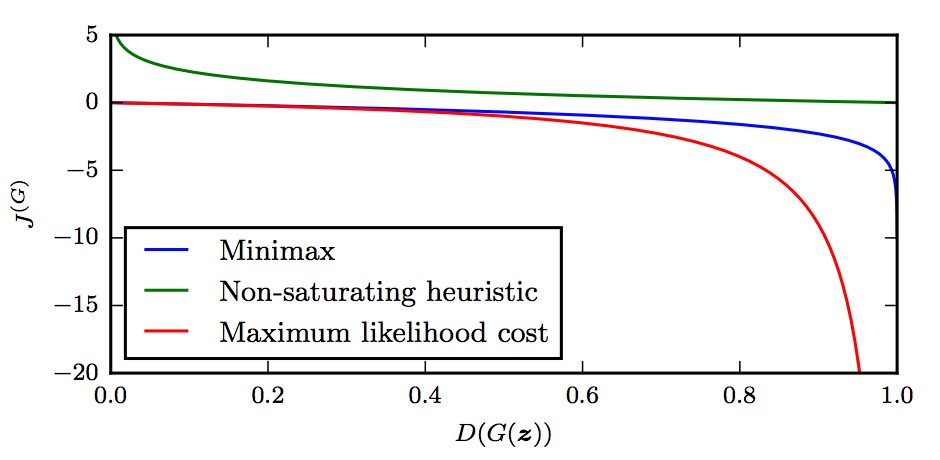
Minimax:其实就是零和游戏(zero-sum game),生成器的代价函数等于判别器代价函数的负值。可以证明,这等价于最小化数据与模型之间的JS散度(Jenson-Shannon divergence)。但是这个代价函数其实是存在着隐患的。一般来说,判别器训练的收敛速度比生成器快得多,因此判别器很快就能以较高的置信度将生成器生成的假样本给拒绝掉,从而造成生成器的梯度消失的问题。这一缺陷可以用下面的方法来解决。 $$ J^{(G)} = -J^{(D)} \
V (\theta ^{(D)}, \theta ^{(G)}) = J^{(D)} (\theta ^{(D)}, \theta ^{(G)}) \
\theta ^{(G)*} = \underset{\theta ^{(G)}}{\operatorname{argmin}} \underset{\theta ^{(D)}}{\operatorname{max}} V (\theta ^{(D)}, \theta ^{(G)}) $$Heuristic, non-saturating game:我们可以换种方式来思考问题:在minimax game中,我们是让生成器最小化判别器判对的对数概率,这会导致一些问题;那么可不可以让生成器来最大化判别器判错的对数概率呢?显然也是可以的,并且这也能避免生成器梯度消失的问题。这是一种启发式的方法,其动机是为了让玩家(也就是生成器)在“输掉”游戏的时候能得到比较强的梯度。 $$ J^{(G)} = - \frac{1}{2} \mathbb{E}_{z} \log (D(G(z))) $$
从下图可以看出,heuristicly designed non-saturating cost在$D(G(z))$变化的时候,其方差较小,因此是比较合适作为生成器代价函数的选择的。
DCGAN
DCGAN即使用了全卷积网络的GANs,一般特指这篇paper中的网络结构。目前几乎所有的GANs都或多或少地借鉴了DCGAN的架构。DCGAN的主要创新点在于:
- 同时在判别器与生成器网络中使用了Batch Normalization层。当然,为了能够学到真实数据分布正确的均值(mean)与规模(scale),判别器的首层与生成器的末层没有加BN层。
- 整个网络架构借鉴了the all-convolutional net(不是FCN),不含pooling和“unpooling”层,增加表示维度是靠
stride=1的转置卷积(transposed convolition)实现的。
总而言之,就是换了原始的GAN中的网络架构,把FC层都换成了带BN层的卷积层。
WGAN & WGAN-GP
What does it mean to learn a probability distribution?
WGAN在paper开头就直截了当地提出了一个问题,我们怎么样才算是学到了一个概率分布呢?如果按照本文开头的说法,我们的做法是先定义一个参数化的概率密度族$(P_\theta )_{\theta \in \mathbb{R}}$,然后通过在已有的数据集${x^{(i)}} ^m_{i=1}$上最大化似然的方法来找到一个最佳的参数,并将这个参数对应的那个概率密度$P_{\theta}$视为我们所学习到的模型。 $$ \underset{\theta \in \mathbb{R}}{\max} \frac{1}{m} \sum ^m_{i=1} \log P_{\theta} (x^{(i)}) $$ 如果真实的数据分布$\mathbb{P}_r$存在密度,而我们学习到的概率密度$P_{\theta}$所对应的概率分布为$\mathbb{P}_{\theta}$,则上述学习过程实际上等价于最小化$\mathbb{P}_r$与$\mathbb{P}_{\theta}$之间的KL散度$KL(\mathbb{P}_r \parallel \mathbb{P}_{\theta})$。这也是上文提到过的。
是不是看起来有理有据令人信服?但是,这上面的推理过程有一个很重要很显而易见但是又常常为人所忽视的条件,那就是首先$\mathbb{P}_r$与$\mathbb{P}_{\theta}$之间的KL散度必须存在,然后我们才能去最小化这个KL散度,来获取最优$\theta$。你TM在逗我,KL散度还能不存在?事实上,这是很常见的。比如说我们用GANs生成样本的时候,输入的随机噪声通常就是一个64维的向量,然后经过生成器网络来生成一个$64\times64=4096$维的图片,其本质还是决定于开始的那个64维的随机向量。64维相对于4096维来说实在是微不足道,也就是说,生成样本分布的支撑集(support)构成了高维空间上的低维流形(manifold),撑不满整个高维空间。那么该模型的流形与真实分布的支撑集之间很有可能就没有不可忽视的交集(non-negligible intersection),以致两者间的KL散度不存在,或者说是$\infty$。
KL散度都不存在了,那还优化个毛?不过这难不倒千千万万机智的研究者。你不是要让这两个概率分布有交集吗,那我就往$\mathbb{P}_{\theta}$上加噪声,加个大点的噪声总是能让这两个分布碰在一起的,那KL散度不是就有了?这也是几乎所有的生成模型都包含了噪声项的原因。一般来说,在训练开始的时候加的噪声要大一点,让含有噪声的两个分布能够够得着。随着训练过程的深入,两个分布的主体开始慢慢靠近,这时候噪声就需要慢慢减小了。最后两个分布开始真正有了不可忽视的交集,那么此时加不加噪声也没什么关系了。
不过这种方法也是存在着一些问题的,加噪声很可能使得生成出来的样本比较模糊(blurry)。如果加的是mean=0.1的高斯噪声,而像素值本身又已经归一化到了$[0,1]$,那么很显然,这个噪声相对于像素值来说太大了。于是机智的研究者在论文里展示生成的样本的时候,不像他们在训练过程中干的那样,是不怎么加噪声的。换句话说,加噪声虽然在一定程度上保证了KL散度的存在,也就是使得极大似然方法能够奏效,但是这对于问题本质上来说并没有改善,并非解决问题的正确方法(走上了邪路^_^)。
与其显式地估计有可能并不存在的$\mathbb{P}_r$的密度,不如直接将来自先验分布$p(z)$的随机变量$\mathcal{Z}$通过参数化的映射$g_\theta : \mathcal{Z} \to \mathcal{X}$来生成样本$\mathcal{X}$,只要这个映射出来的样本$\mathcal{X}$的分布服从或者接近$\mathbb{P}_r$,那不就是学到了真实的概率分布?VAEs和GANs就是这么做的。这么做有两个好处,首先其与直接估计密度的方法不同,能够表示被约束在低维流形的概率分布;同时直接生成样本有时候比得到一个干巴巴的概率密度更加有用。
那么问题又转移到了,如何衡量生成样本分布$\mathbb{P}_{\theta}$与真实样本分布$\mathbb{P}_r$之间的相似性或者说距离$\rho(\mathbb{P}_{\theta}, \mathbb{P}_r)$?这个距离度量需要有比较好的性质,不能两个分布没有交集就直接歇菜了(说的就是KL散度你这个大坑货)。WGAN论文之后的部分就在讲如何定义一个好的距离度量,并将其应用在GANs中。
各个距离度量的一个基本的差异在于它们对于成序列的概率分布的收敛性的影响。一个概率分布的序列$(\mathbb{P}_t)_{t\in\mathbb{R}}$能够收敛,当且仅当存在一个$\mathbb{P}_\infty$使得$\rho(\mathbb{P}_{\theta}, \mathbb{P}_r)$趋向于零,也就是说取决于$\rho$的定义。一般来说,如果$\rho$在拓扑(topology)上越弱,则序列越容易收敛。
为了优化生成模型的参数$\theta$,我们希望定义的模型能够使得映射$\theta \mapsto \mathbb{P_\theta}$连续。这里的连续指的是当一连串的参数$\theta_t$收敛于一个值$\theta$,概率$\mathbb{P}_{\theta_t}$也能收敛于$\mathbb{P}_\theta$。不过这种连续性取决于我们选择的距离度量。距离度量越弱,概率分布越容易瘦脸,则越容易定义一个从$\theta$空间到$\mathbb{P}_\theta$空间的连续的映射。我们这里关注映射$\theta \mapsto \mathbb{P_\theta}$连续性的原因是,我们希望$\theta \mapsto \rho(\mathbb{P}_{\theta}, \mathbb{P}_r)$的损失函数是连续的(方便梯度下降训练),而这等价于在使用距离度量$\rho$的情况下映射$\theta \mapsto \mathbb{P_\theta}$连续。
Different Disrances
令$\mathcal{X}$为紧致的度量集合(例如图像空间$[0,1]^d$),$\Sigma$为$\mathcal{X}$的Borel子集,$\operatorname{Prob}(\mathcal{X})$为$\mathcal{X}$上的概率度量空间,则可以定义两个分布$\mathbb{P}_r, \mathbb{P}_g \in \operatorname{Prob}(\mathcal{X})$之间的距离或是散度如下:
TV距离(The Total Variation distance) $$ \delta (\mathbb{P}_r, \mathbb{P}_g) = \underset{A\in\Sigma}{\sup} |\mathbb{P}_r (A) - \mathbb{P}_g(A)| $$
KL散度(The Kullback-Leibler divergence):注意KL散度是不对称的,而且在例如$P_g (x) = 0$且$P_r (x) > 0$的情况下会变成无穷。 $$ KL(\mathbb{P}_r \parallel \mathbb{P}_g) = \int \log \left( \frac{P_r (x)}{P_g (x)} \right) P_r (x) d \mu (x) $$
JS散度(The Jensen-Shannon divergence):其中$\mathbb{P}_m= (\mathbb{P}_r + \mathbb{P}_g) / 2$。JS散度是对称的,并且始终是有定义的。DCGAN的生成器的损失函数就是JS散度形式的,但是JS散度也会导致一些问题。 $$ JS(\mathbb{P}_r, \mathbb{P}_g) = KL(\mathbb{P}_r \parallel \mathbb{P}_m) + KL(\mathbb{P}_g \parallel \mathbb{P}_m) $$
EM距离(The Earth-Mover distance or Wasserstein-1):其中$\prod(\mathbb{P}_r, \mathbb{P}_g)$表示所有边际概率为$\mathbb{P}_r$与$\mathbb{P}_g$的联合分布$\gamma (x,y)$的集合。直观地说,$\gamma (x,y)$表示了为了将分布$\mathbb{P}_r$变换成$\mathbb{P}_g$所需要的从$x$移到$y$的”质量“的多少。而EM距离则代表了最优搬运方案的代价。 $$ W(\mathbb{P}_r, \mathbb{P}_g) = \underset{\gamma\in\prod(\mathbb{P}_r, \mathbb{P}_g)}{\inf} \mathbb{E} _{(x,y)\sim \gamma} \left[ \parallel x- y\parallel \right] $$
为了比较这几个距离度量的优劣,WGAN设计了一个例子:令$Z \sim U[0,1]$,$\mathbb{P}_0$为$(0, Z) \in \mathbb{R}^2$的分布($x$坐标为$0$,$y$坐标为$Z$,实际上就是分布在点$(0,0)$到点$(0,1)$这条线段上)。令生成样本分布为$g_\theta (z)=(\theta, z)$,其中以$\theta$作为唯一的实值参数(实际上就就是沿着$x$轴左右移动之前提到的线段)。
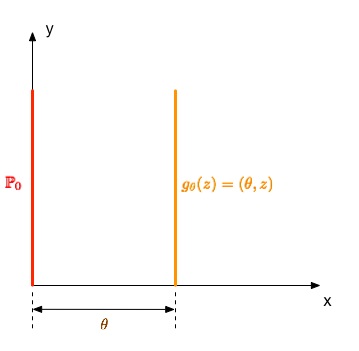
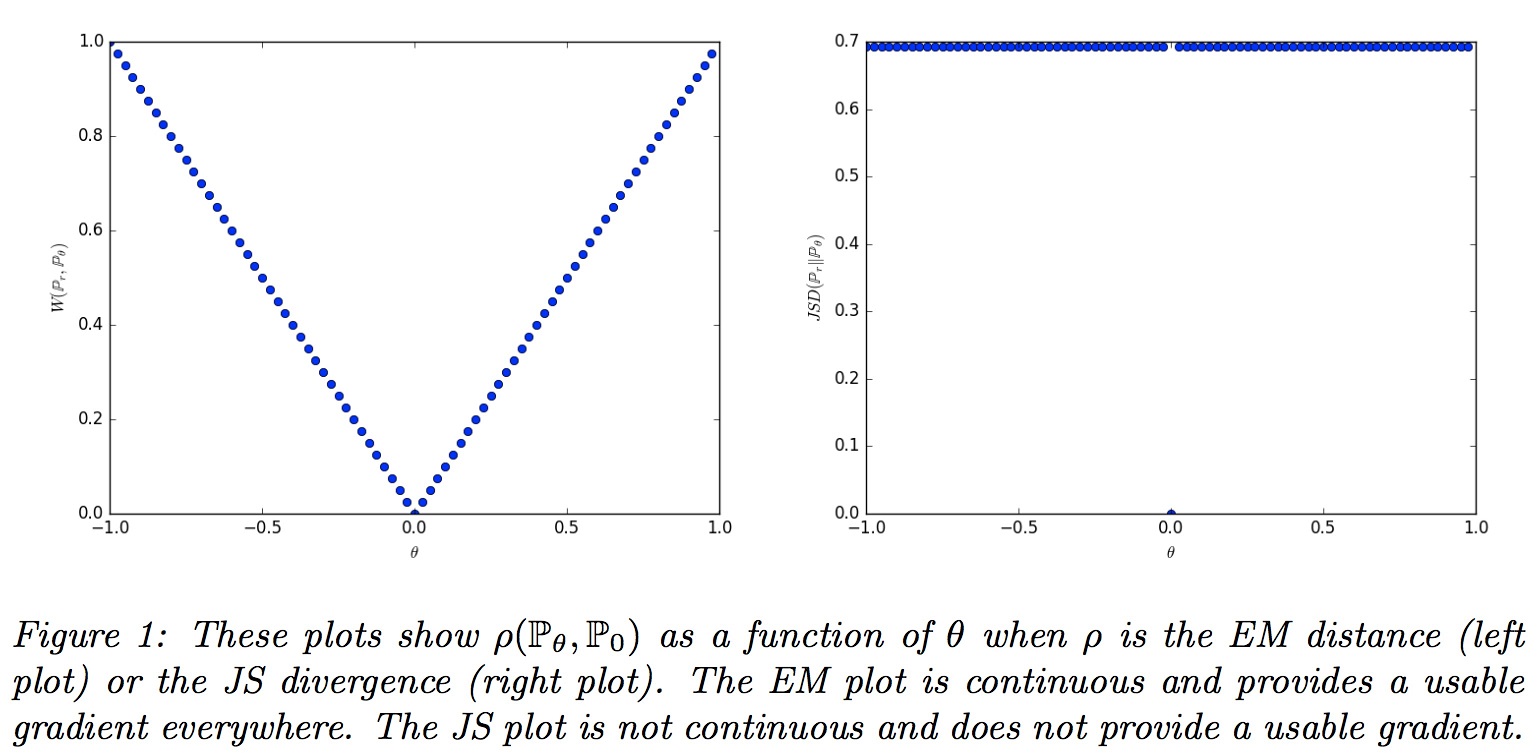
则前文所述的各个距离度量的表达式为:
- $W(\mathbb{P}_\theta, \mathbb{P}_0) = |\theta|$
- $JS(\mathbb{P}_\theta, \mathbb{P}_0) = \begin{cases} \log 2, & \text{if } \theta \ne 0 \\ 0, & \text{if } \theta = 0 \end{cases}$
- $KL(\mathbb{P}_\theta, \mathbb{P}_0) = (\mathbb{P}_0, \mathbb{P}_\theta) = \begin{cases} +\infty, & \text{if } \theta \ne 0 \\ 0, & \text{if } \theta = 0 \end{cases}$
- $\delta(\mathbb{P}_\theta, \mathbb{P}_0) = \begin{cases} 1, & \text{if } \theta \ne 0 \\ 0, & \text{if } \theta = 0 \end{cases}$
可以看出,当$\theta _t \to 0$,只有EM距离能够使得序列$(\mathbb{P}_{\theta _t}) _{t \in N}$收敛于$\mathbb{P}_0$,而其他的JS散度、KL散度、KL散度取反或者TV距离都不能。这说明在EM距离下,我们能够通过梯度下降的方式习得低维流形上的概率分布,而在其他距离度量下甚至连损失函数的连续性都不能保证,更遑论习得概率分布了。一句话,EM距离大法好!因此,WGAN将EM距离(又称Wasserstein-1距离)作为两个概率分布之间的距离度量,从而推导损失函数的表达式。
Wasserstein GAN
从上面的例子可以看出,Wasserstein距离比JS散度具有更优良的性质。(当然,WGAN原论文里面还有一大堆数学推导来证明,这里就不列了。)但是,Wasserstein距离的原始公式是很难计算的(intractable)。WGAN里使用了一个Kantorovich-Rubinstein duality的定理,将EM距离的式子转换为: $$ W(\mathbb{P}_\theta, \mathbb{P}_0) = \frac{1}{K} \underset{\parallel f \parallel _L \le K}{\sup} \mathbb{E}_{x\sim \mathbb{P}_r} - \mathbb{E}_{x\sim \mathbb{P}_\theta} [f(x)] $$ 这里的$f(x)$需要是K-Lipschitz函数,也就是说要求$\exists K\in \mathbb{R},K\ge0$,使得对于实值函数$f(x)$定义域内的任意$x_1$与$x_2$,都满足下式: $$ |f(x_1)-f(x_2)| \le K |x_1-x_2| $$ 假设我们有一个符合K-Lipschitz条件的函数族${f_w}_{w\in \mathcal{W}}$,那么就变成了解决以下问题: $$ \underset{w\in\mathcal{W}}{\max} \mathbb{E} _{x\sim \mathbb{P}_r} [f_w (x)] - \mathbb{E} _{z\sim p(z)} [f_w (g_\theta (z))] $$ 这个函数族自然是可以用一个含参$w\in \mathcal{W}$的神经网络来表示,但是如何满足K-Lipschitz条件呢?需要注意的是,整个函数族${f_w}_{w\in \mathcal{W}}$需要符合条件,但我们并不关心$K$的具体值。因此WGAN论文中提出了一种简单粗暴的做法,把权重的值域$\mathcal{W}$限制在一个非常小的范围内,比如说$\mathcal{W} = [-0.01, 0.01]$,也就是$w \in [-0.01, 0.01]$。这么一来,$\partial f_w / \partial x$也会被限制在一定范围内,则$\exists K\in \mathbb{R},K\ge0$使得$f_w$满足K-Lipschitz条件。当然这种做法很粗糙,也会导致某些问题,这些问题与解决放将在之后的WGAN-GP小节中详述。
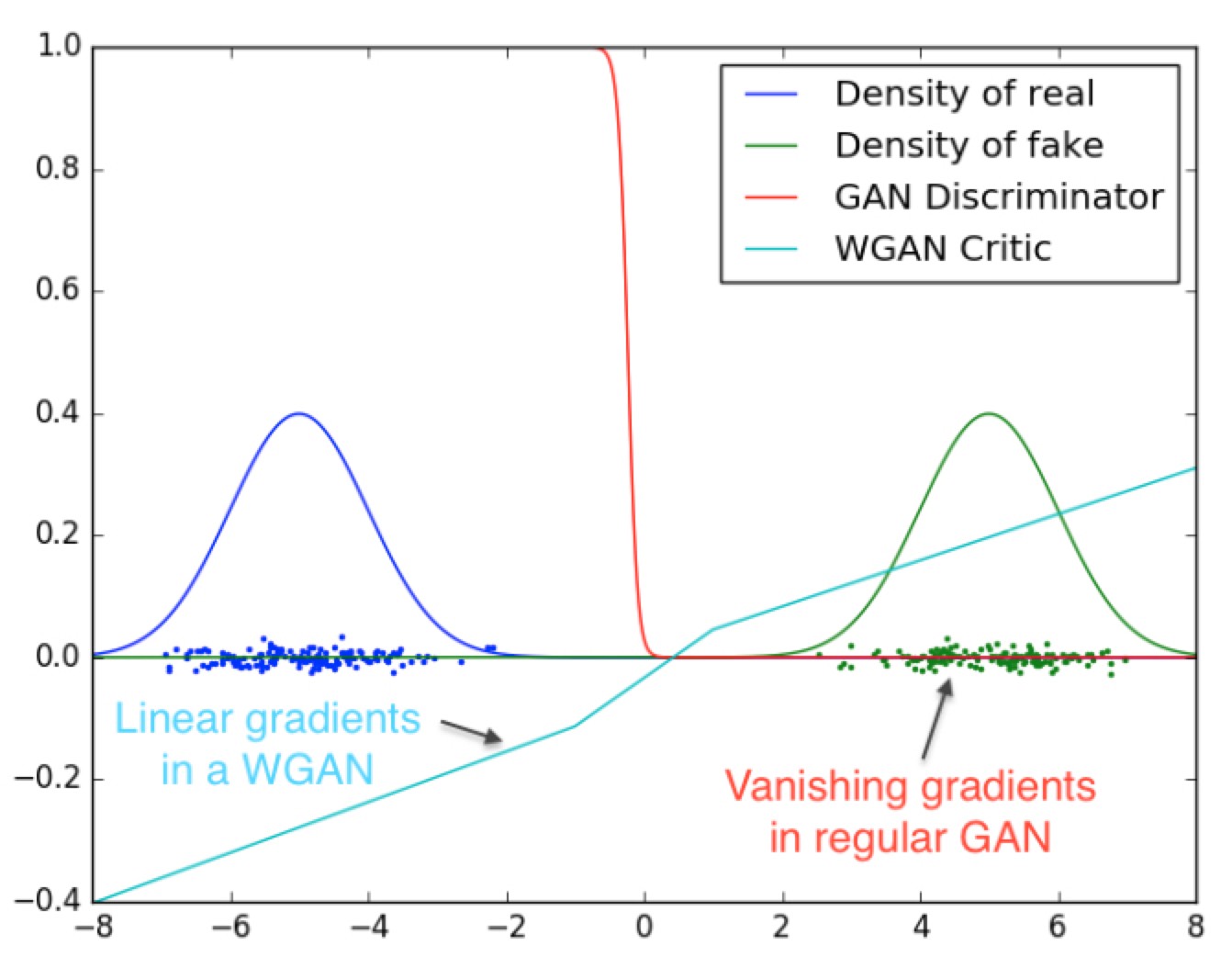
WGAN又做了一个实验,如下图所示,判别器学习区分真假两个高斯分布。可以看出用了JS散度的判别器虽然能很快就把这两个样本分布判别出来,但是在左右两端都处于饱和状态,根本提供不了梯度信息。而用了Wasserstein距离的判别器(文中称作critic)则几乎能在任何位置都提供线性的梯度信息,这对于生成器的训练来说是非常重要的。
到此为止,WGAN所使用的Wasserstein距离就介绍完了。损失函数定义如下:
$$
\mathcal{L}_D = \mathbb{E} _{z\sim p(z)} [f_w (g_\theta (z))] - \mathbb{E} _{x\sim \mathbb{P}_r} [f_w (x)] \
\mathcal{L}_G = - \mathbb{E} _{z\sim p(z)} [f_w (g_\theta (z))]
$$
具体到网络训练上,相对于DCGAN的主要改进有:
- 判别器与生成器的loss不用log
- 判别器不用Sigmoid层
- 优化器更新参数之后将权重限制在一个非常小的区间$\mathcal{W}$内
- 使用RMSprop而非基于动量的优化器
- 在初始阶段多训练判别器几次($n_{critic}=100$),保证判别器在初始的时候就已经达到一个比较好的水准,增加训练的稳定性
WGAN训练过程的伪代码如下所示:

除了改善网络训练的稳定性之外,WGAN所使用的Wasserstein距离还是一个非常好的训练程度的指示器。但是JS散度就没有这个作用。
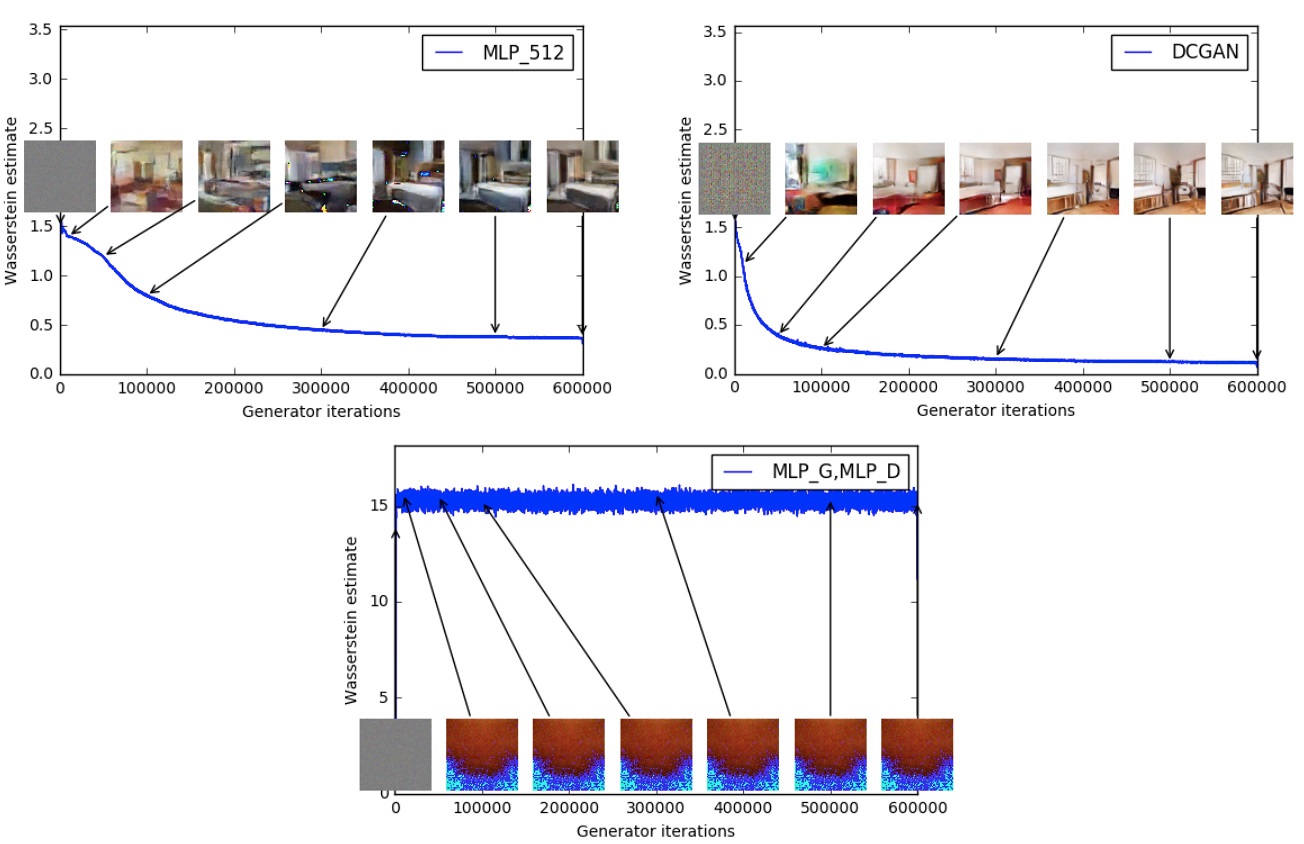
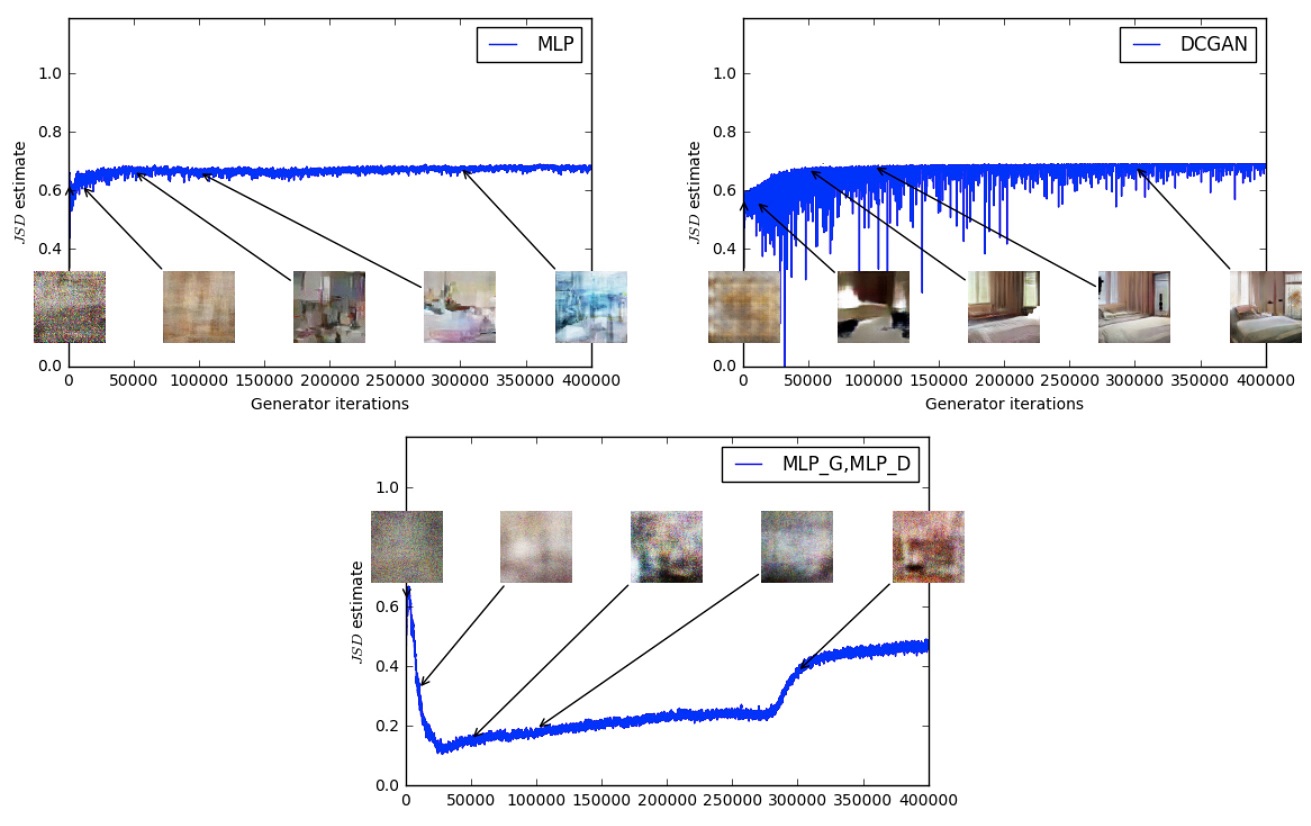
使用Wasserstein距离与使用JS散度训练出来的DCGAN,在正常情况下生成样本质量是差不多的:

但是,WGAN还能在生成器去掉BN层之后依然得到比较好的生成样本,原始DCGAN就直接崩了。

此外,如果都用MLP而不是CNN,WGAN的质量会稍差一些,但是使用JS散度训练出来的DCGAN还会有多样性不足(mode collapse)的缺陷。

WGAN-GP
上面提到,WGAN让$f_w$满足K-Lipschitz条件的方法很粗暴,直接将整个网络的权重都限制在了一个很小的区间内。这样做其实是会导致一些问题的。
- 第一个问题是weight clipping不能充分利用神经网络的容量(capacity underuse)。如下图所示,左图第一排是WGAN估计的分布(value surface),第二排是WGAN-GP估计的分布。可以明显看出,WGAN基本上都是用矩形来近似,没有像WGAN-GP那样学到数据样本更高层的变化趋势。从右图的第二幅图可以看出,经过充分训练的WGAN网络的权值基本上就分布在了$-c$与$c$两个端点上,中间几乎没有权值分布。这简直就像二值神经网络一样了,难怪网络的容量不能得到充分利用。
- 第二个问题是梯度消失与梯度爆炸(exploding and vanishing gradients)。从右图的第一幅图可以看到,在不用BatchNorm的时候,weight clipping的常数$c$稍有不同,就会使得梯度随着网络一层层传播而指数增长或者衰减,从而导致梯度消失或者爆炸。
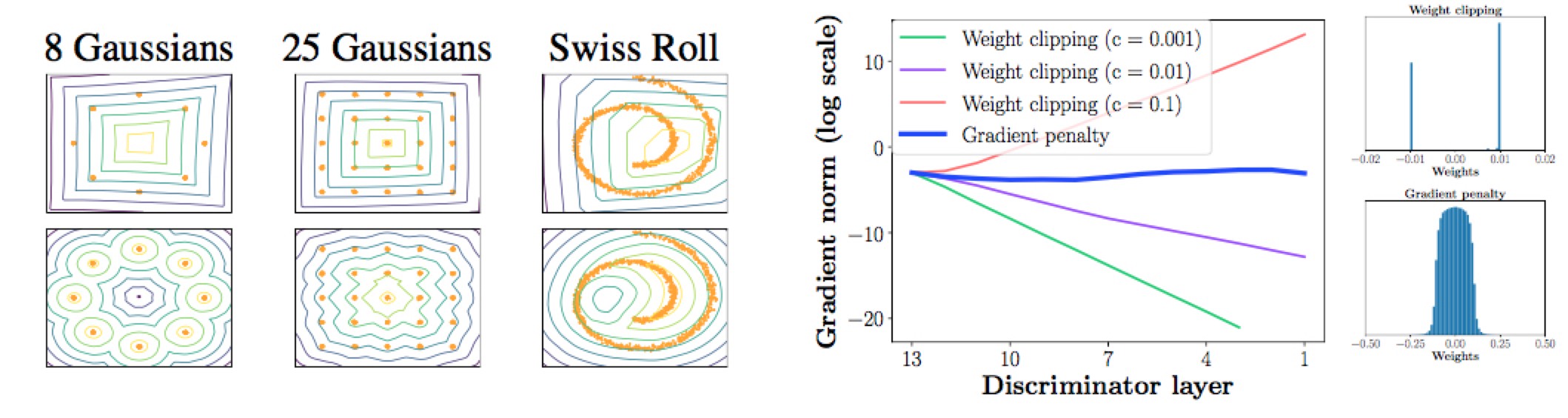
针对这两个问题,WGAN的作者又想出了新的操作——gradient decay。新的操作能够解决上述的两个问题,让WGAN的训练过程更加稳定(好像上次WGAN对DCGAN的时候也是这么讲的:cry:)。
上面说了,weight clipping是为了让网络函数$D(x)$满足Lipschitz条件才用的,并不是非它不可。既然表现这么差,那我们能不能换一种方法来做Lipschitz约束呢?gradient decay就是这样被想出来的。我们回顾一下Lipschitz条件的定义,是要求函数$D(x)$在它的值域上满足$\forall x_1, x_2, \parallel \nabla D(x) \parallel _p \le K$。于是作者们在判别器的损失函数上加了一个梯度的惩罚项,鼓励梯度的范数趋近于K(或者说是1,反正1-Lipschitz与K-Lipschitz条件只是差了常数倍) $$ L = \underset{\tilde{x} \sim \mathbb{P}_g}{\mathbb{E}} [D(\tilde{x})] - \underset{x \sim \mathbb{P}_r}{\mathbb{E}} [D(x)] + \lambda \underset{\hat{x} \sim \mathbb{P}_{\hat{x}}}{\mathbb{E}} [(\parallel \nabla _{\hat{x}} D(\hat{x})\parallel _2 -1)^2] $$ 这里有几个需要注意的地方:
最优判别器的一个特性(properties of the optimal WGAN critic):为什么惩罚项是鼓励梯度绝对值趋向于$K$,而不是只是让梯度在$[-K, K]$之间呢?这就牵扯到WGAN训练出来的最优判别器的一个性质。假设我们随机采到了两个样本$x_r \sim \mathbb{P} _ r$和$x_g \sim \mathbb{P} _ g$,那么对所有在其连线$x_t = (1-t)x_g + t x_r$上的点的梯度就是$\nabla D(x_t) = \frac{x_r - x_t}{\parallel y - x_t \parallel}$。换句话说,在$\mathbb{P}_r$与$\mathbb{P}_g$内,以及两者的中间地带,最优判别器的梯度基本上都是1(或者说$K$)。
$\mathbb{P}_{\hat{x}}$的采样分布(sampling distribution):在计算$\lambda \underset{\hat{x} \sim \mathbb{P}_{\hat{x}}}{\mathbb{E}} [(\parallel \nabla _{\hat{x}} D(\hat{x})\parallel _2 -1)^2]$的时候,需要把期望$\mathbb{E}$转换为采样然后取平均。然而这个$\mathbb{P}_{\hat{x}}$要求我们在整个样本空间$\mathcal{X}$上采样,这种在高维空间指望用采样来估计期望的方法显然是不可实现的,会导致维度灾难。于是文中将$\mathbb{P}_{\hat{x}}$的采样定义为在沿着真实分布$\mathbb{P}_r$的一堆点与生成分布$\mathbb{P}_g$的一堆点的直线上均匀采样。从实验效果上来说,这是很有效的。
惩罚系数(penalty coefficient):取$\lambda=10$,作者称无论在Toy数据集还是大规模的ImageNet数据及上都是work的。
不要用Batch Normalization:gradient penalty惩罚的是单个对单个的样本,而BN会把这样单个的映射变成整个batch的所有输入到整个batch的输出,引入了不同采样之间的依赖关系,这样GP就不能用了。作者推荐用Layer Normalization。
双边惩罚(two-sided penalty):惩罚项鼓励梯度从正负两边来趋向1(或者说$K$),作者称这样能收敛到更好的最优点,速度更快,而且对于判别器来说不会造成太大的约束。
WGAN-GP相对于WGAN的改进就是上面这些了,其算法的伪代码如下。

接下来看看实验结果:
- WGAN-GP的收敛速度明显比WGAN快,虽然在wall time上还是比不过DCGAN,但是WGAN-GP在训练的稳定性上犹有过之。
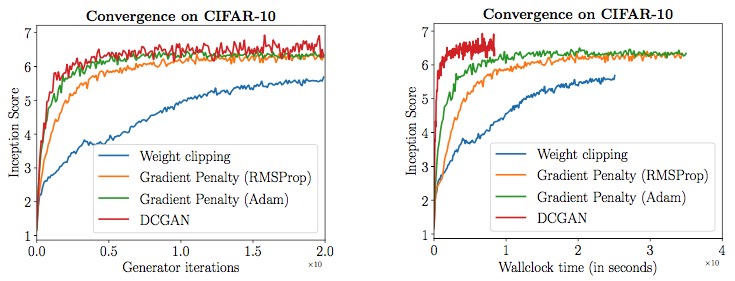
- 同时,在面对之前的一些困难的训练条件(比如说不用BN层甚至不用任何normalization),WGAN-GP都能够稳定训练并且结果良好。特别是面对ResNet-101这么高层的网络,只有WGAN-GP能训练出结果。

GANs in Practice
MLP-GAN
使用多层感知机(MLP)来构建判别器与生成器的网络,可以说得上是最为简单的GANs了。可以根据这个来摸清楚GANs自身的一套工作流程到底是怎么样的,为之后实现复杂的GANs网络做个铺垫。本小节相关代码在GAN-Zoo/GAN中。
首先我们需要训练集,比如说我们这里用到的MNIST数据集。PyTorch在这点上做得很好,对于一些常用的数据集都自带有loader,不用自己写了。相关代码见GAN-Zoo/GAN/data_loader.py。
有了数据集之后就需要自己定义模型的网络结构了,具体到GANs就是判别器与生成器的定义。这里贴一段判别器的定义,可以看出PyTorch在网络定义方面还是很方便的(和Keras差不多)。
|
|
定义完模型,之后就是整个网络的训练过程了:
- 初始化阶段:初始化models、criterion(
nn.BCELoss())以及optimizer(nn.optim.Adam()),检查cuda是否可用(nn.cuda.is_available()),能用的话就上GPU跑。 - 网络训练阶段:
- 训练判别器:主要分为两个步骤,首先从数据集中读取样本,判别器forward一遍,然后和真实标签(
1)做loss并backward;其次,生成随机噪声而后经过生成器的forward得到生成样本,再喂给判别器,与虚假标签(0)做loss并backward。最后由optimizer更新判别器网络的参数。 - 训练生成器:首先生成随机噪声,而后通过生成器网络生成虚假样本,再通过判别器网络得到loss,并更新生成器网络。值得注意的是,生成器的loss的计算用的是真实标签(
1),也就是上述的heuristicly designed non-saturating cost。 - 输出log并保存model
- 训练判别器:主要分为两个步骤,首先从数据集中读取样本,判别器forward一遍,然后和真实标签(
非常简单的代码,但是生成出来的数字的效果还是很不错的。

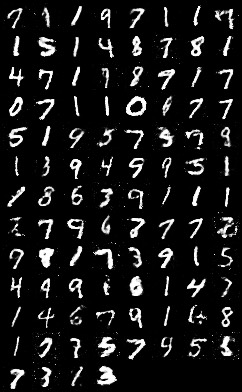
第一张是MNIST数据集中的,第二张是通过GANs生成的(300次迭代)。虽然第二张还有些不尽如人意之处(迭代次数太少),但是总体上来说,已经非常接近真实的数字图片了。这就是GANs的威力!
DCGAN
DCGAN与MLP-GAN的代码相差不多,基本上就是重新写一遍model的事。为了测试DCGAN的capacity,我将MNIST数据集换成了CIFAR-10数据集。相关代码见GAN-Zoo/DCGAN。
不过这次的结果只能说是差强人意,20次迭代后生成的图像还算不错(毕竟CIFAR-10的分辨率是28*28):

但是继续训练的话,GANs训练不稳定的问题就出现了。到24次迭代的时候,由于判别器已经非常精准,导致生成器的loss固定在了27左右动弹不得,从而生成的图像变成了一团噪声:
|
|

不过到了第25次迭代,DCGAN似乎又略微恢复了正常:
|
|
{kind=link}
当然,让GANs训练变得稳定的方法不是没有,这里就列举了不少tricks:
- 避免稀疏的梯度:不要使用ReLU或者Max Pooling,尽量用LeakyReLU;
- 使用软标签(soft and noisy labels),也就是说真实标签与虚假标签不要是固定的
1或者0,最好加点噪声上去; - 在真实样本的输入上也加点随时间衰减的噪声
- 给生成器加Dropout层
- ……
这样的trick是还有很多,有些我试过确实有用,还有些则不是很确定,属于玄学范畴。不过与其用一大堆tricks,还不如直接简单粗暴地上WGAN吧!
WGAN
相关代码见GAN-Zoo/WGAN。WGAN在实现上主要有以下几点需要注意:
- 判别器模型的输出不过Sigmoid层,而是取平均之后flatten到1维,输出的是Wasserstein距离而非分类结果。(code)
- 由于判别器器在一个epoch中需要训练多次,因此不能用
for..in..来loop整个书记,而是用iterator来迭代循环。(code) - 在生成器训练过25次之前,或者是之后每500次的时候,判别器在每个epoch内都需要训练100次而非默认的5次。这是为了让判别器在一开始就达到差不多最优的状态。(code)
- 为了提升效率,优化生成器的时候用判别器得到loss不更新判别器的梯度(code),优化判别器用生成器生成虚假样本时也不更新生成器的梯度(code)。
- 在生成器的optimizer更新权值之后clamp所有的权值,使其在一定范围内,以满足K-Lipschitz条件。(code)
WGAN-GP
相关代码见GAN-Zoo/WGAN-GP。WGAN-GP在实现上与WGAN的主要区别在于:
- 用gradient penalty代替了weight clipping。这里面涉及到计算梯度的梯度,这在PyTorch 0.2.0版本前是无法做到的,我猜大概也是因为这个原因,原作者选择了用TensorFlow来实现WGAN-GP。关于在低版本的PyTorch上实现gradient penalty的讨论见此。PyTorch版本更新之后增加了
torch.autograd.grad这么一个函数,能够满足我们的需求。 - 在判别器中不使用Batch Normalization,详细原因在前文已经给出。可以选择的替代有Layer Normaliztion,Weight Normalization等。
在代码与实验中,有以下几点需要注意:
- 在训练的初始阶段,由于增大了判别器的训练次数(1个epoch训练100次),判别器接近最优,导致刚开始的loss非常大(~ -150000)。在判别器训练次数恢复正常后(1个epoch训练5次),loss的绝对值逐渐下降到几千几百的级别。迭代10000次左右即收敛到比较好的效果。
- 我的代码实现里,对于判别器模型没有使用任何Normalization,加上的话收敛速度应该会有一定提升。
Further Reading
最后总结一些我在学习过程中看过的比较好的资料以及代码实现:
- pytorch-tutorial: 我见到的最好的PyTorch入门教程,简洁清晰明了,有其他DL框架使用经验以及Python基础的朋友适用。一上来看不懂的话,可以先看官方的60分钟入门教程之后,再看这个。
- NIPS 2016 Tutorial: Generative Adversarial Networks: Iran Goodfellow在NIPS2016上的教程演讲,很好地介绍了GANs的基本思想和应用。前面的数学推导看不懂的话,可以结合DeepLearningBook(中译版已经上市,本人忝为校对之一)。同时,还可以结合slides看,slides上的都写得很简练,tutorial中则做了详细的说明。可惜的是,当时WGAN及其变种还没有出来,因此在这篇tutorial中没有提到。
- 几篇代表论文以及相关的代码实现:
- GAN: paper, code (pytorch-tutorial)
- DCGAN: paper, code (PyTorch official example), code (pytorch-tutorial)
- WGAN: paper, code (PyTorch)
- WGAN-GP: https://arxiv.org/abs/1704.00028, code (PyTorch)
- 我自己对上述论文的代码实现,欢迎指正:GAN-Zoo
- 一些有趣的GANs应用
- Create Anime Characters with A.I. !:一篇非常有意思的技术文章,生成的头像插图质量非常高。(online demo)