Notes: From Faster R-CNN to Mask R-CNN
Contents
That’s my notes for the talk “From Faster-RCNN to Mask-RCNN” by Shaoqing Ren on April 26th, 2017.
Yesterday – background and pre-works of Mask R-CNN
Key functions
- Classification - What are in the image?
- Localization - Where are they?
- Mask (per pixel) classification - Where+ ?
- More precise to bounding box
- Landmarks localization - What+, Where+ ?
- Not only per-pixel mask, but also key points in the objects
Mask R-CNN Architecture
Classification

Please ignoring the bounding box in the image
$$ \text{class} = Classifier(\text{image}) $$
Problems
- High-level semantic concepts
- High efficiency
Solutions
- SIFT or HOG (about 5 or 10 years ago)
- Based on edge feature (low- level semantic infomations)
- Sometimes mistake two objects which people can distinguish easily
- e.g. mark the telegraph pole as a man
- CNN (nowadays)
- Based on high-level semantic concepts
- Rarely mistake objects. If it do so, people are likely to mix up them, too.
- Translation invariance
- Scale invariance
Detection
 $$
\text{location}=Classifier(\text{all patches of an image)}
$$
\text{location}=Classifier(\text{all patches of an image)}
\text{precise_location}=Regressor(\text{image}, \text{rough_location})
$$
Problems
- High efficiency
Solutions
- Traverse all patches of an image and apply image classifier on them, then patches with highest scores are looked as locations of objects.
- As long as the classifier is precise enough, and we are able to traverse millions of patches in an image, we can always get a satisfactory result.
- But the amount of calculations is too large. (about 1 or 10 millon)
- Do Regression cosntantlty, starting from a rough location of an object, and finally we’ll get the precise object location.
- Low amount of calculations. (about 10 or 100 times)
- Hard to locate many adjacent and similar objects
- The state-of-the-art methods tend to use exhaustion on large-scale, and refine the rough localtions by regression on small-scale.
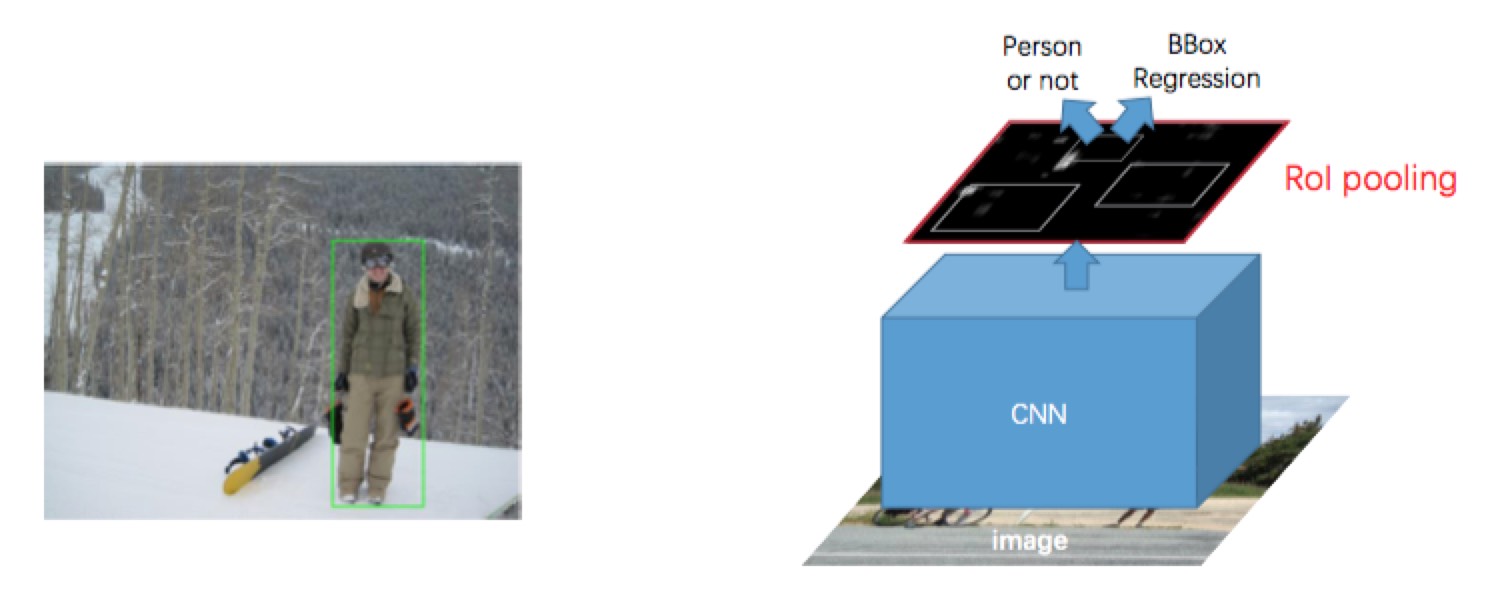
R-CNN

- Use region proposal to decline millions of patches into 2~10k.
- Use classifier to determine the class of a patch
- Use BBox regression to refine the location
SPP-net / Fast R-CNN
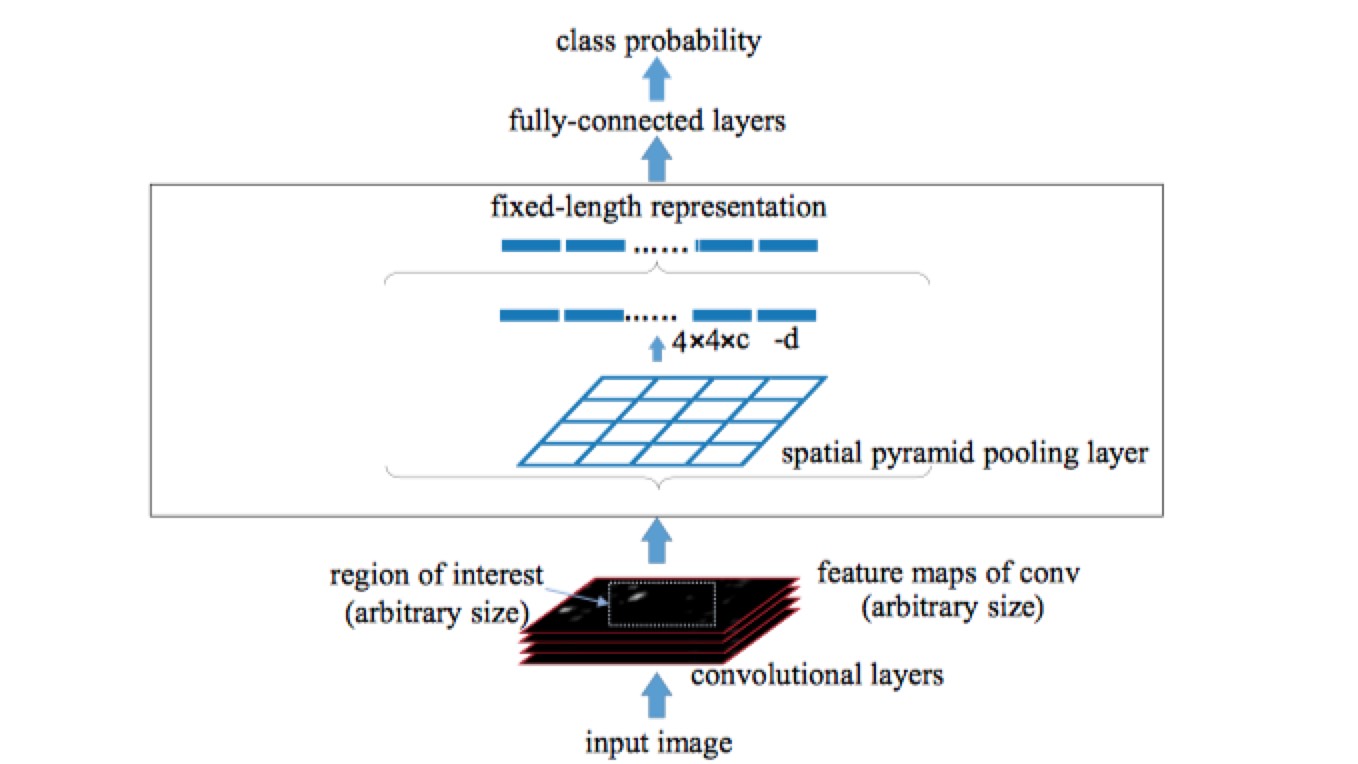
- Use Pyramid Pooling / RoI-Pooling to generate a fixed-length representation regardless of image size/scale
Faster R-CNN
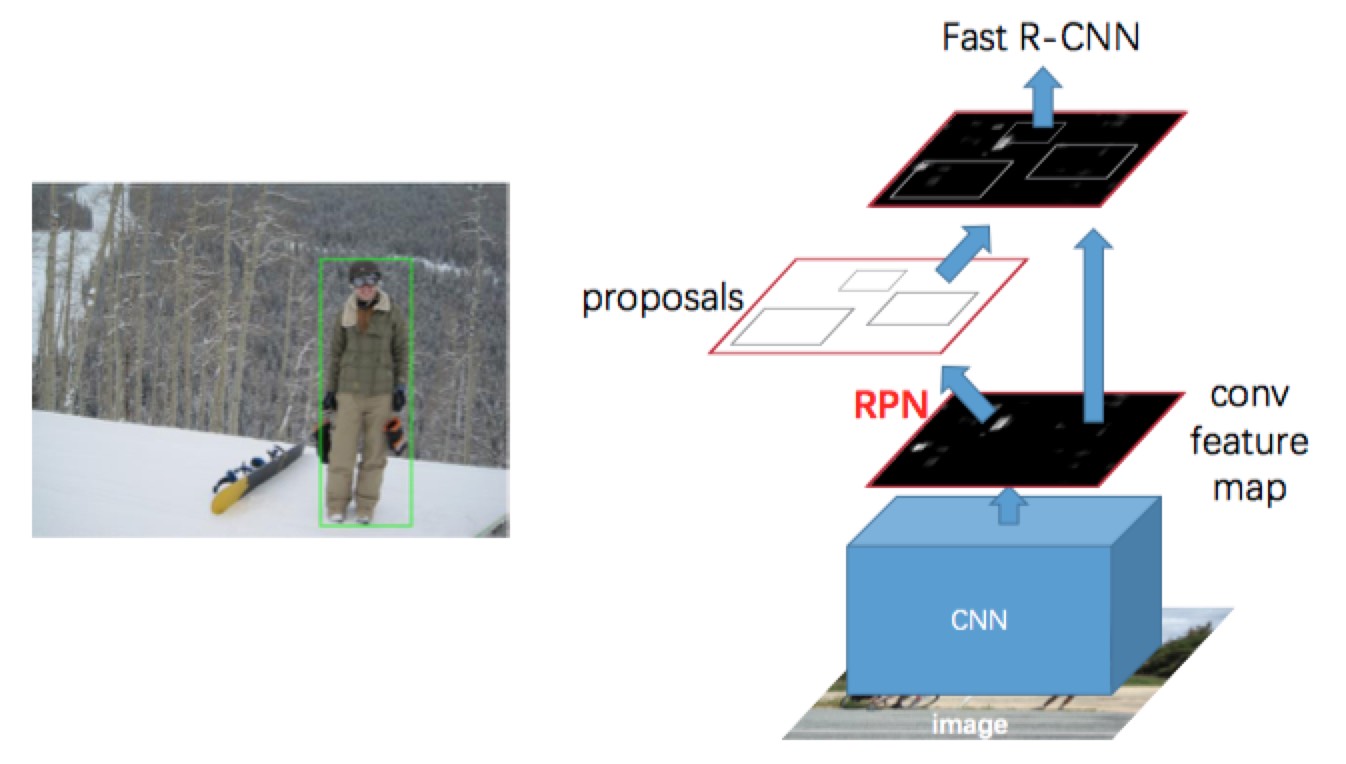
- Use RPN (Region Proposal Network) that shares full-image convolutional features with the detection network, thus enabling nearly cost-free region proposals.
- An RPN is a fully convolutional network that simultaneously predicts object bounds and objectness scores at each position.
- The RPN is trained end-to-end to generate high-quality region proposals, which are used by Fast R-CNN for detection.
- We further merge RPN and Fast R-CNN into a single network by sharing their convolutional features—using the recently popular terminology of neural networks with ‘attention’ mechanisms, the RPN component tells the unified network where to look.
- Number of patches: $width \times height \times scales \times ratios$
scalestands for the size of image and objectsratiostands for the aspect ratio of filter

Different schemes for addressing multiple scales and sizes.
- Pyramids of images and feature maps are built, and the classifier is run at all scales.
- Pyramids of filters with multiple scales/sizes are run on the feature map.
- Faster R-CNN use pyramids of reference boxes in the regression functions, which avoids enumerating images or filters of multiple scales or aspect ratios.
SSD / FPN
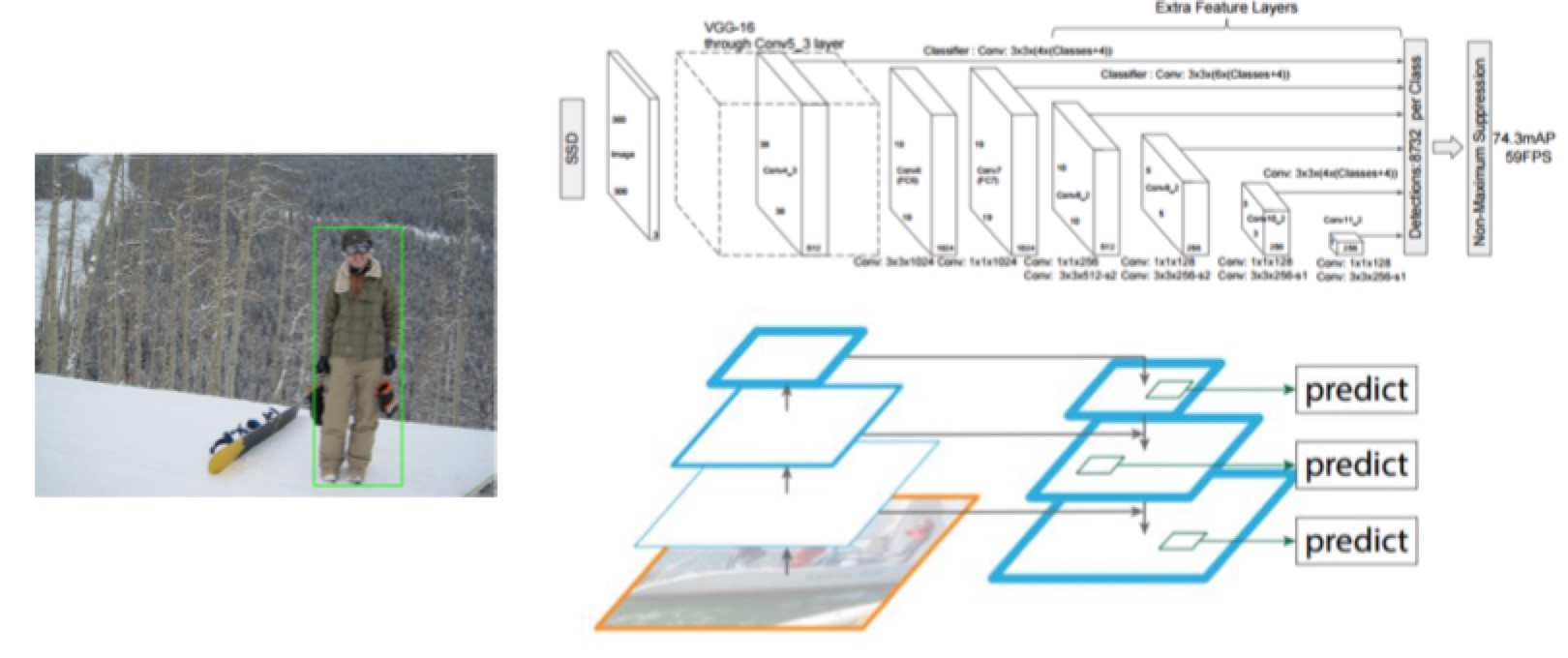
- FPN (Feature Pyramid Network) exploit the inherent multi-scale, pyramidal hierarchy of deep convolutional networks to construct feature pyramids with marginal extra cost. A top-down architecture with lateral connections is developed for building high-level semantic feature maps at all scales.
Instance Segmentation
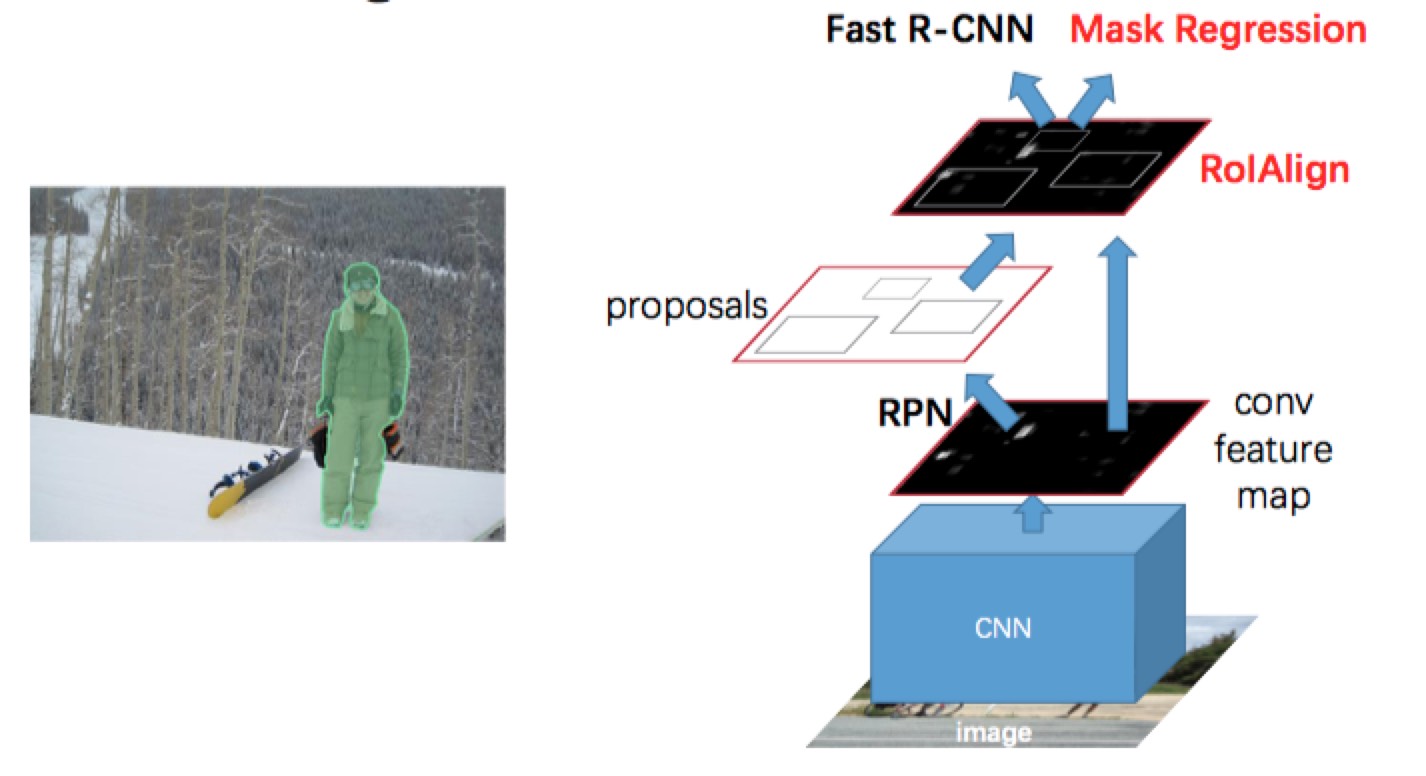
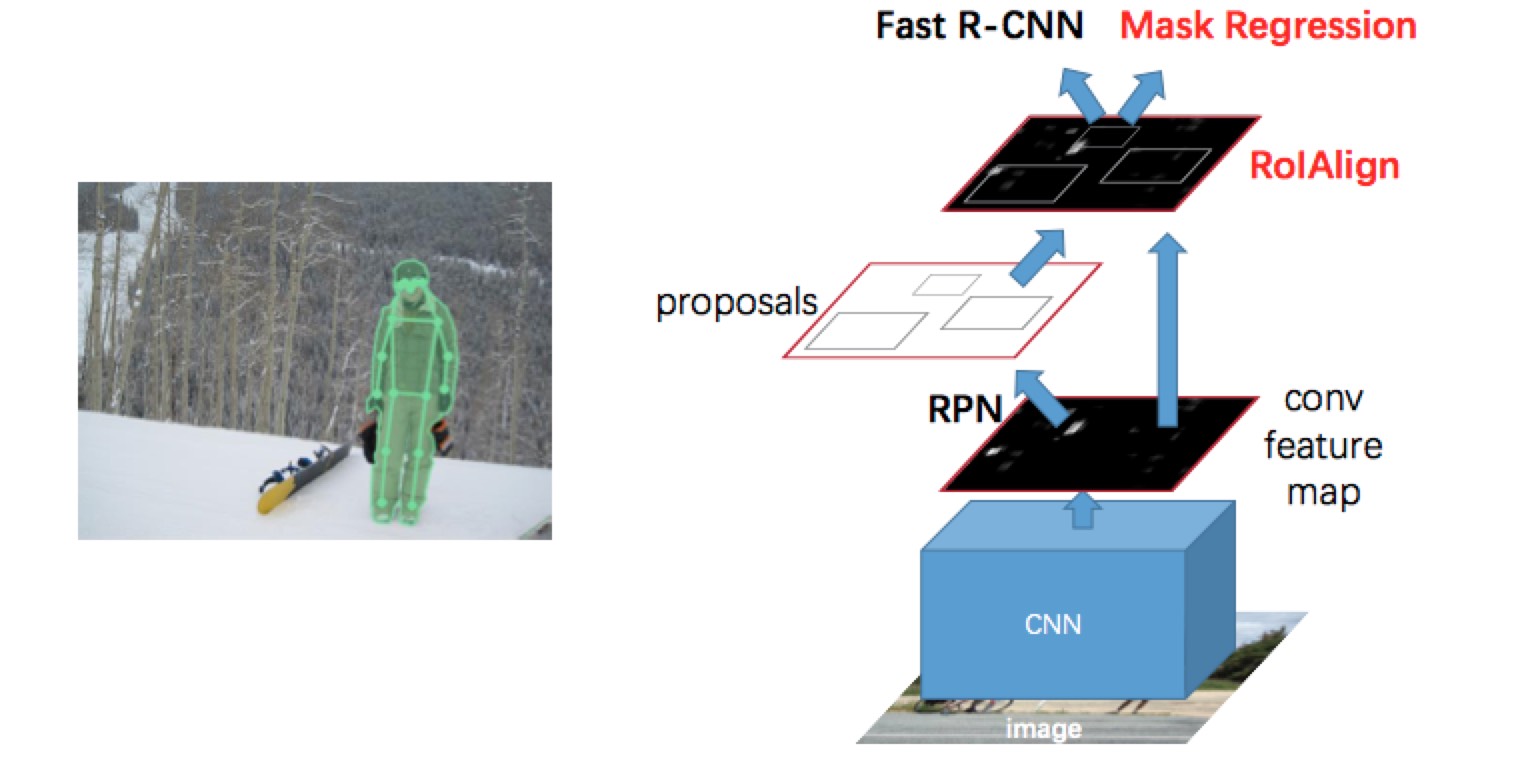
- Use Mask Regression to predict instance segmentation based on object bounding box.
- Replace RoI Pooling with RoI Align
Keypoint Detection
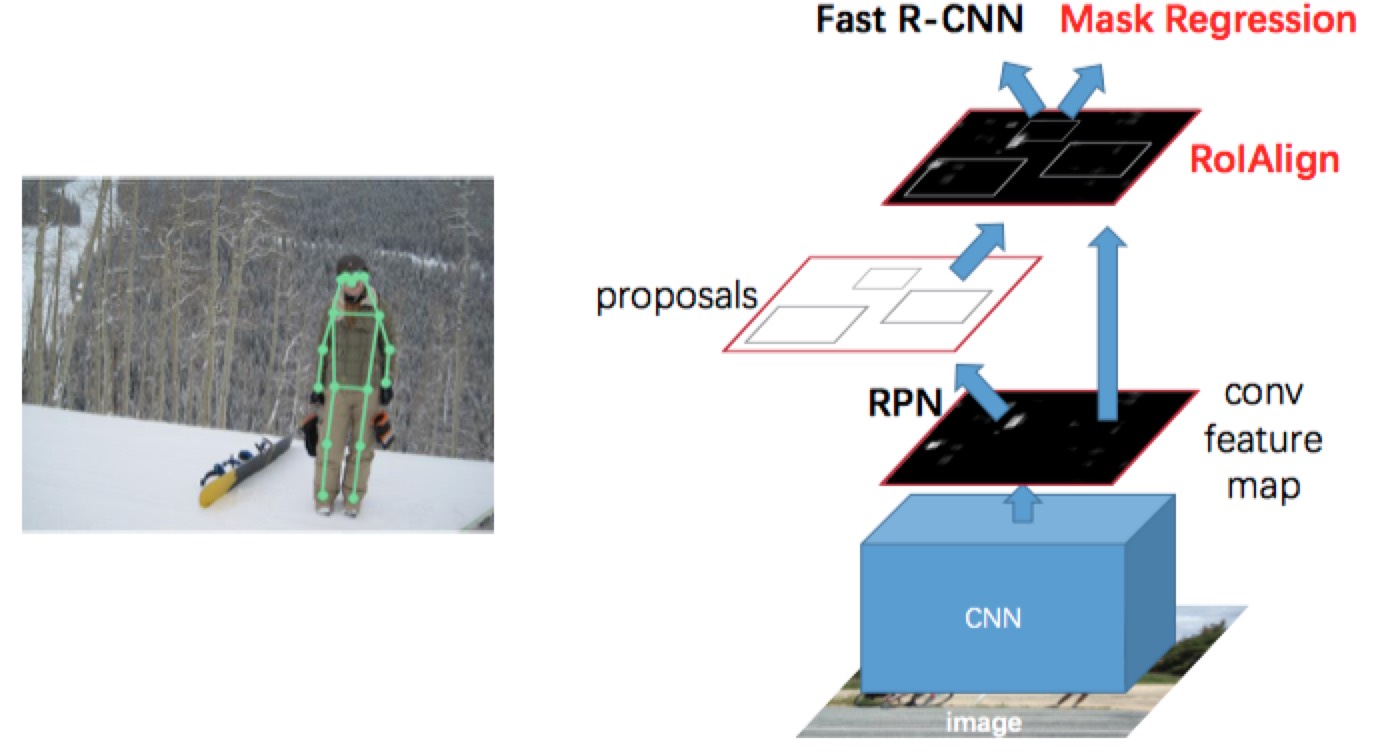
- We make minor modifications to the segmentation system when adapting it for keypoints.
- For each of the $K$ keypoints of an instance, the training target is a one-hot $m \times m$ binary mask where only a single pixel is labeled as foreground.
Today - details about Mask-RCNN and comparisons
RoI Align
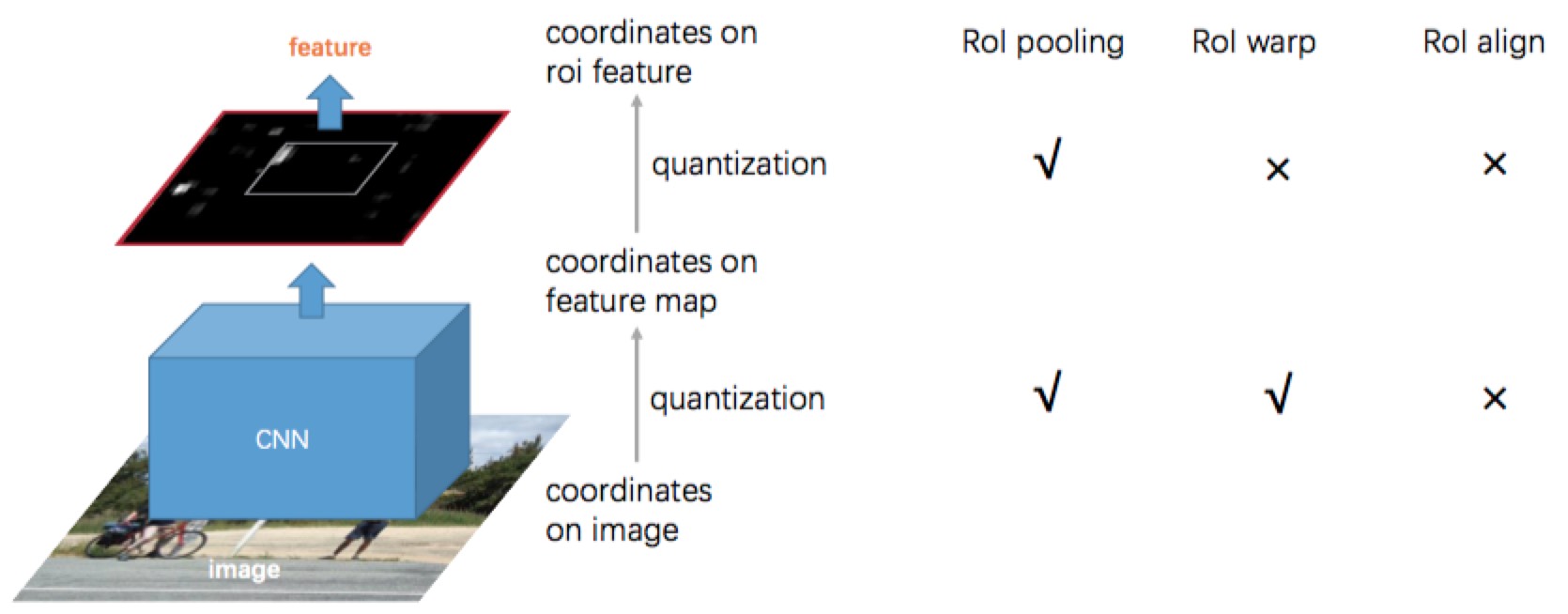
- RoI pooling contains two step of coordinates quantization: from original image into feature map (divide by stride) and from feature map into roi feature (use grid). Those quantizations cause a huge loss of location precision.
- e.g. we have two boxes whose coordinate are 1.1 and 2.2, and the stride of feature map is 16, then they’re the same in the feature map.
- RoI Align remove those two quantizations, and manipulate coordinates on continuous domain, which increase the location accuracy greatly.
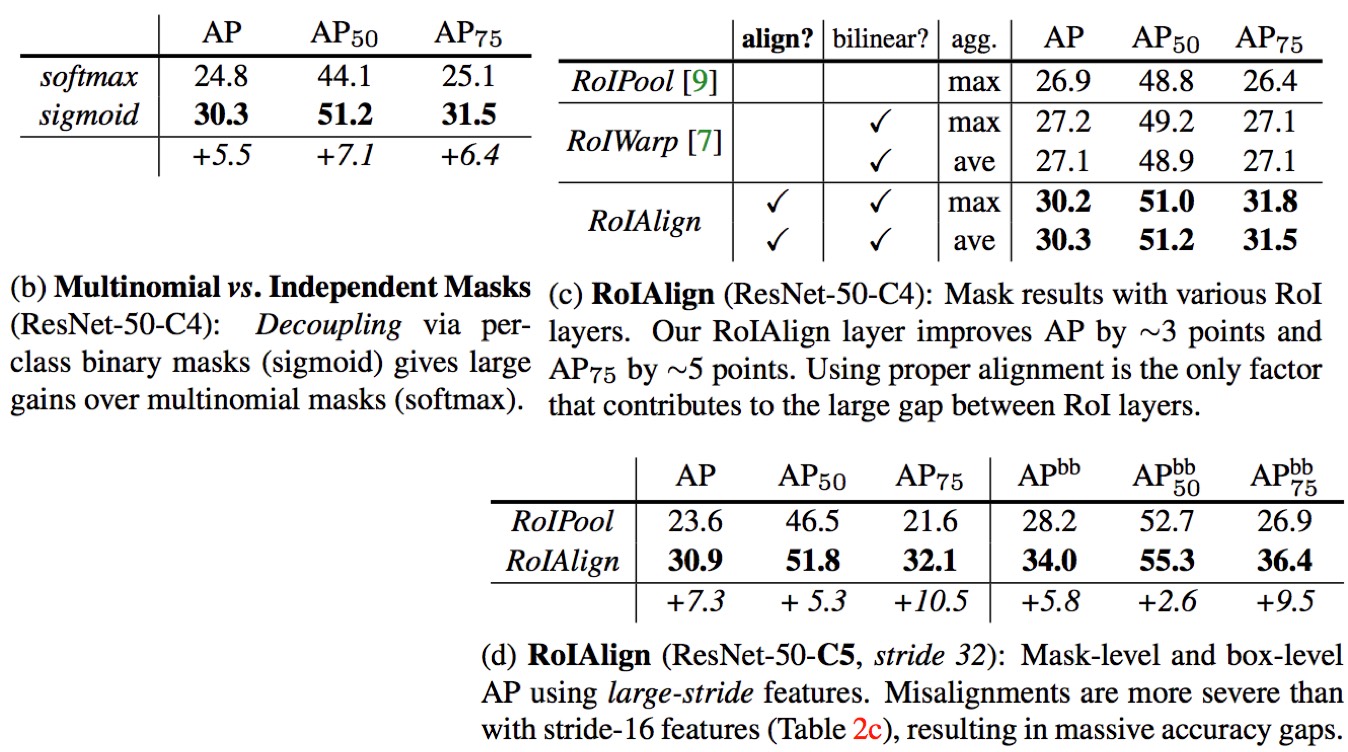
- RoI Align really improves the result.
- Moreover, note that with RoIAlign, using stride-32 C5 features (30.9 AP) is more accurate than using stride-16 C4 features (30.3 AP, Table 2c). RoIAlign largely resolves the long-standing challenge of using large-stride features for detection and segmentation.
- Without RoIAlign, AP in ResNet-50-C4 is better than that in C5 with RoIPooling, i.e., large stride is worse.Thus many precious work try to find methods to get better results in smaller stride. Now with RoIAlign, we can consider whether to use those tricks.
Multinomial vs. Independent Masks
- Replace softmax with sigmoid.
- Mask R-CNN decouples mask and class prediction: as the existing box branch predicts the class label, we generate a mask for each class without competition among classes (by a per-pixel sigmoid and a binary loss).
- In Table 2b, we compare this to using a per-pixel softmax and a multinomial loss (as com- monly used in FCN). This alternative couples the tasks of mask and class prediction, and results in a severe loss in mask AP (5.5 points).
- The result suggests that once the instance has been classified as a whole (by the box branch), it is sufficient to predict a binary mask without concern for the categories, which makes the model easier to train.
Multi-task Cascade vs. Joint Learning
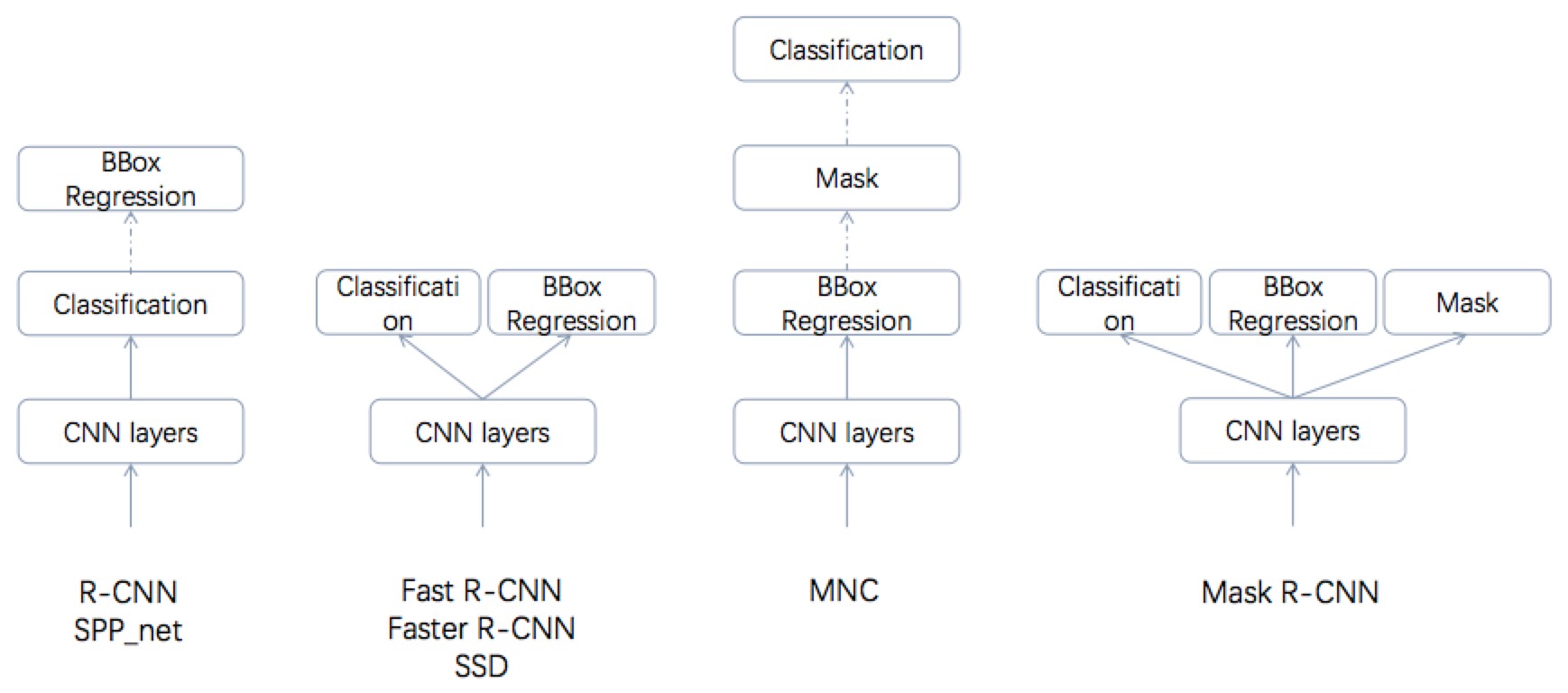
- Cascading and paralleling are adopted alternately.
- On training time, three tasks of Mask R-CNN are paralleling trained.
- But on testing time, we do classification and bbox regression first, and then use those results to get masks.
- BBox regression may change the location of bbox, so we should wait it to be done.
- After bbox regression, we may adopt NMS or other methods to reduce the number of boxes. That decreases the workload of segmenting masks.
- Adding the mask branch to the box-only (i.e., Faster R-CNN) or keypoint-only versions consistently improves these tasks.
- However, adding the keypoint branch reduces the box/mask AP slightly, suggest- ing that while keypoint detection benefits from multitask training, it does not in turn help the other tasks.
- Nevertheless, learning all three tasks jointly enables a unified system to efficiently predict all outputs simultaneously (Figure 6).
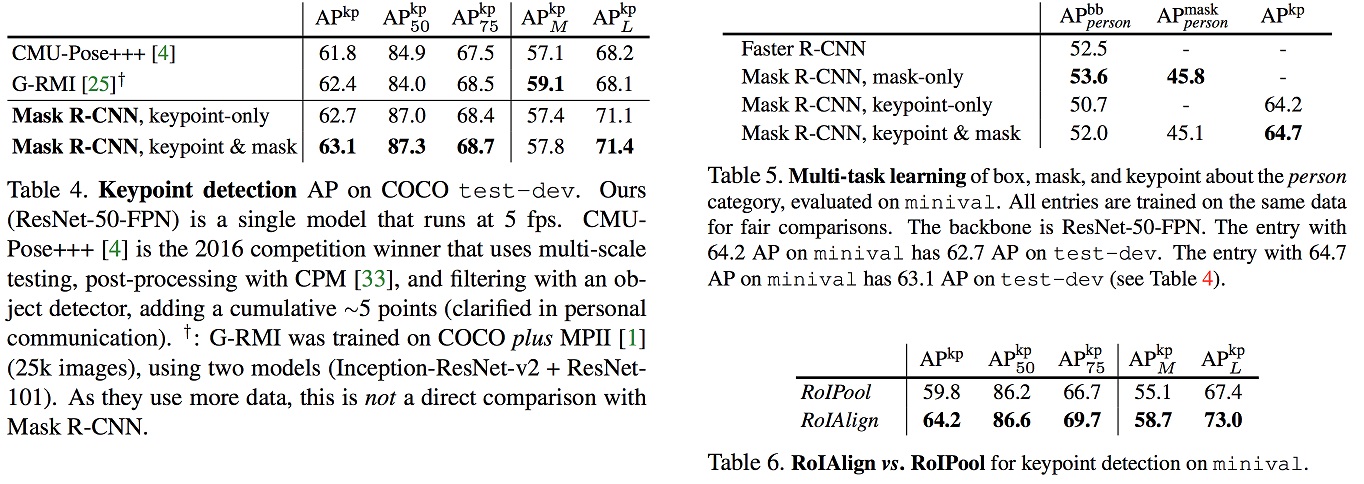
Comparison on Human Keypoints
- Table 4 shows that our result (62.7 APkp) is 0.9 pointshigher than the COCO 2016 keypoint detection winner [4]that uses a multi-stage processing pipeline (see caption ofTable 4). Our method is considerably simpler and faster.
- More importantly, we have a unified model that can si-multaneously predict boxes, segments, and keypoints whilerunning at 5 fps.
Results


Future - discussion
Order of key functions?
- Order of classification, localization, mask classification and landmarks localization?
- Top down or Buttom up?
- Mask R-CNN uses Top-down method.
- the COCO 2016 keypoint detection winner CMU-Pose+++ uses Buttom-up method.
- Detect key points first (don’t know which keypoint belongs to which person)’
- Then gradually stitch them together
Precious & semantic label

box-level label -> instance segmentation & keypoints detection -> instance seg with body parts
Semantic 3D reconstruction

Future
- the performance & system improves rapidly
- join a team, keep going
- always try, thinking and discussion
- understand and structure the world