Notes for Object Detection: One Stage Methods
Contents
In this post, we focus on two mainstreams of one-stage object detection methods: YOLO family and SSD family. Compared to two-stage methods (like R-CNN series), those models skip the region proposal stage and directly extract detection results from feature maps. For that reason, one-stage models are faster but at the cost of reduced accuracy.
| Model | Resource |
|---|---|
| YOLO | [paper] [code (darknet)] |
| YOLOv2 (YOLO 9000) | [paper] [code (darknet)] [code (PyTorch)] |
| YOLOv3 | [paper] [code (darknet)] [code (PyTorch)] |
| SSD | [paper] [code (Caffe)] [code (PyTorch)] |
| SSD w/ MobileNet | [code (Caffe)] [code (TensorFlow)] [code (PyTorch)] |
| RetinaNet | [paper] [code (PyTorch)] |
R-CNN系列的目标检测方法都是基于region的,也就是说,其检测流程需要分为两个阶段:
- 使用Selective Search或者RPN来生成一定数量的稀疏的RoI
- 使用classifier来对于生成的region proposal进行分类
而one-stage的目标检测方法则不显式地生成region proposal,而是直接从目标可能出现的位置上进行密集采样,然后进行位置回归与类别判断。这么做能够节省生成region proposal的时间,因此相较于two-stage的方法更为简单愉快速,不过这么一来性能可能也会有所下降。
YOLO
YOLO (You Look Only Once)是当时第一个能够实时的目标检测方法,开创了one-stage方法的先河。YOLO这么快是因为它只预测有限个bounding box而不经过生成region proposal的步骤。
Workflow
在大型数据集(例如ImageNet)上用图像分类任务预训练一个CNN网络。
对于一张输入图像,将其分为$S\times S$个cell。当某个物体的预测中心落在了一个cell中时,该cell对检测该物体是否真的在cell内负责。每个cell需要预测:
- $B$个bounding boxes。一个bounding box的信息包含了中心点坐标$(x,y)$和长宽$(w,h)$。其中$(x.y)$的坐标是相对于cell位置的,而且$(x,y,w,h)$都根据输入图像的大小进行归一化,也就是说其值域为$[0,1]$。
- 一个cell内是否存在物体的置信度,其真值为$Pr(Object)\times IoU^{truth}_{pred}$。
- 当物体落在cell内时,物体的类别概率$Pr(Class_i | Object)$。值得注意的是,虽然每个cell有$B$个bounding box,但是每个cell只预测一组类别概率。
总而言之,一张输入图像总共有$S \times S \times B$个bounding box,每个bounding box包含4个定位预测和1个置信度,另外每个cell还要预测$K$个类别概率。所以对于一张输入图像,总计需要预测$S\times S \times (5B+K)$个预测值。这也是网络最后一层的输出数量。
- 把预训练好的CNN网络的最后一层输出数量修改为$S\times S \times (5B+K)$,然后进行训练。
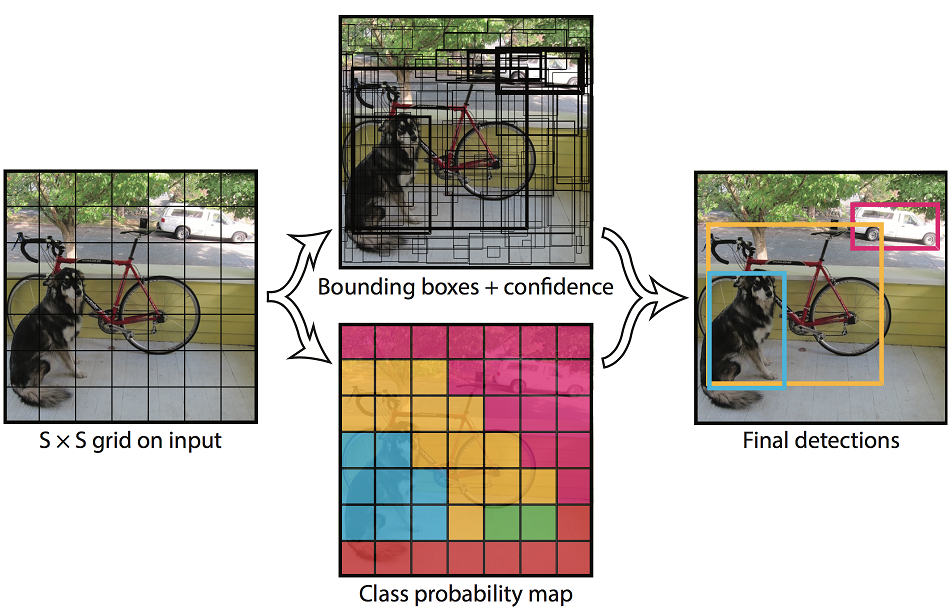
YOLO v1 整体流程 (Source: original paper)
Details
Network Architecture
YOLO的网络结构与GoogLeNet相似,只不过GoogLeNet中的Inception模块被换成了简单的$3\times 3$与$1\times 1$卷积层,最后的FC层的输出维度被修改为$S\times S \times (5B+K)$。
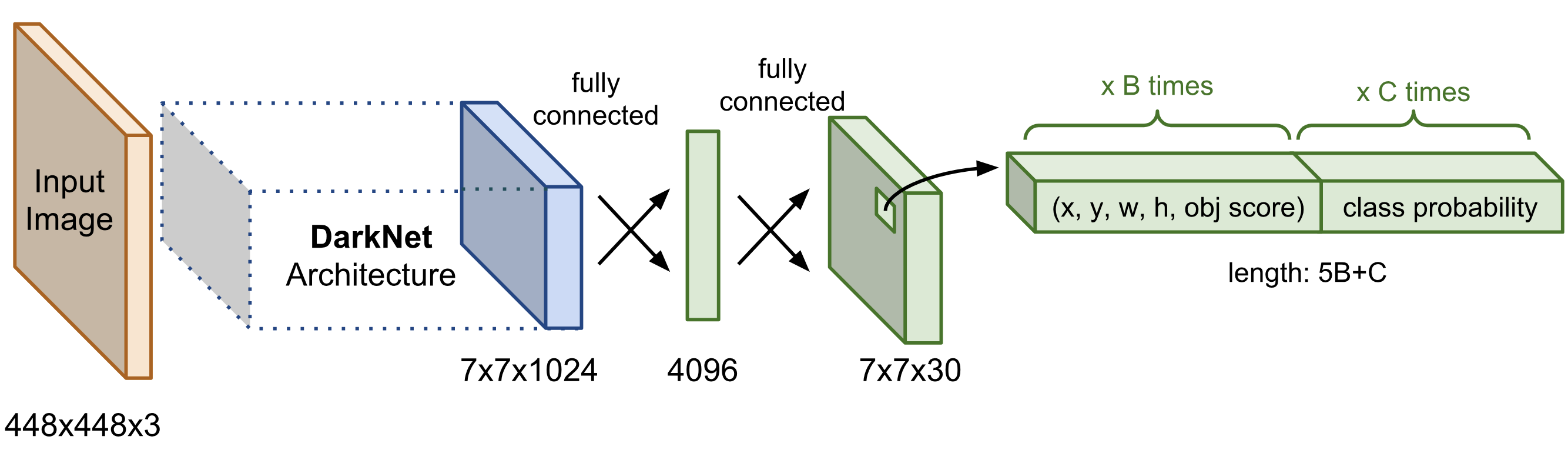
YOLO v1 网络结构 (Source: Lilian Weng's blog post)
Loss Function
YOLO的损失函数氛围定位损失与分类损失两个部分。定位损失主要是bounding box预测位置与真值之间的offset,分类损失则是条件类别概率上的损失。这两者均为SSE (sum of squared error),并且由两个缩放因子$\lambda_\text{coord}$与$\lambda_\text{noobj}$来进行权衡。$\lambda_\text{coord}$用来表示错判定位造成损失的重要程度,$\lambda_\text{coord}$则用来表示错判是否有物体的置信度造成的损失的重要程度。相比较而言,$\lambda_\text{coord}$会更加低一些,因为bounding box之内只存在背景的情况比有物体的更为常见。在原文中,$\lambda_\text{coord}=5$,同时$\lambda_\text{noobj}=0.5$。
其中,
- $\mathbb{1}_{ij}^\text{obj}$表示第$i$个cell中的第$j$个bounding box是否是对该cell内的物体预测负责,即其与ground truth的IoU在相邻的bounding boxes里面是否是最大的
- $\mathbb{1}_{i}^\text{obj}$表示第$i$个cell内是否包含物体
- $C_{ij}$表示第$i$个cell的物体置信度的真值$Pr(Object)\times IoU^{truth}_{pred}$
- $\hat{C}_{ij}$表示第$i$个cell的物体置信度的预测值
- $C$表示所有类别的集合
- $p_i( c )$表示第$i$个cell包含类别$c\in C$的条件概率真值
- $p_i( c )$表示第$i$个cell所预测的包含类别$c\in C$的条件概率
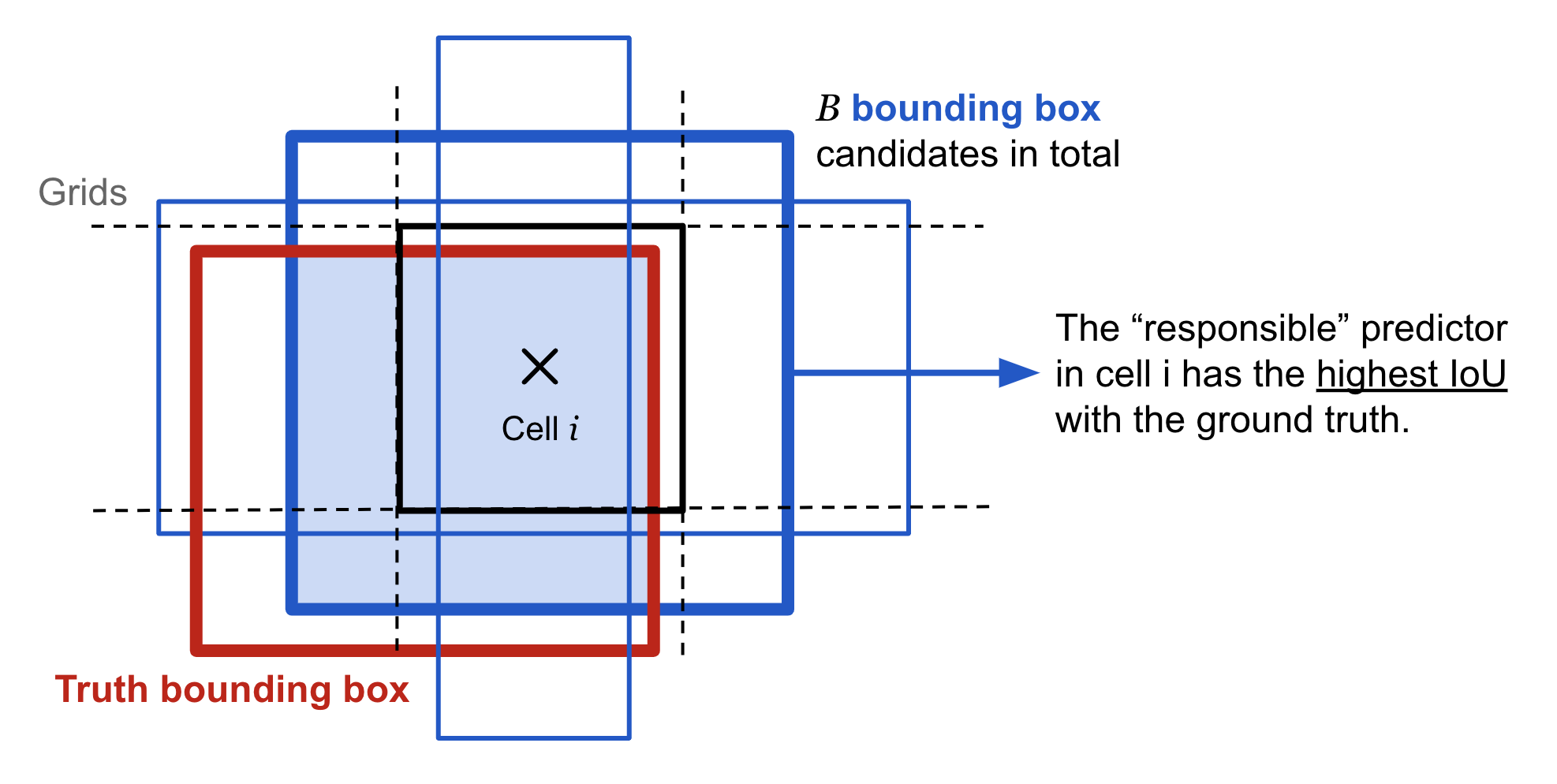
YOLO v1中bounding box对cell内的物体负责 (Source: Lilian Weng's blog post)
可以看出,YOLO所设计的损失函数,只有当物体出现在某个cell中时(即$\mathbb{1}_{i}^\text{obj}=1$),才惩罚其分类错误;同时,只有当某个bounding box对其所在的cell内的物体预测负责时(即$\mathbb{1}_{ij}^\text{obj}=1$),才惩罚其定位错误
Tricks
Drawbacks
YOLO v1开one-stage目标检测方法之先河,速度快。但是由于其只能预测有限个bounding box,对于具有不规则形状的目标或者数量较多的小目标时,其性能就不行了。
SSD
继YOLO之后,SSD时第一个使用CNN的金字塔特征层级(pyramidal feature hierarchy)来实现对于多尺度目标检测的one-stage方法。
具体地说,SSD使用在ImageNet上预训练的VGG-16来提取特征,然后增加了一系列的卷积层来逐步进行降采样,减小feature map的空间尺寸。SSD所增加的这一部分可以得到一个金字塔式的不同尺度的特征表示。从直觉上来说,前面的feature map空间尺寸大、粒度细,比较适合检测小目标;靠后的feature map空间尺寸小、粒度粗,比较适合检测大目标。通过在不同尺寸的feature maps上分别做检测,SSD能够检测不同尺度的物体。
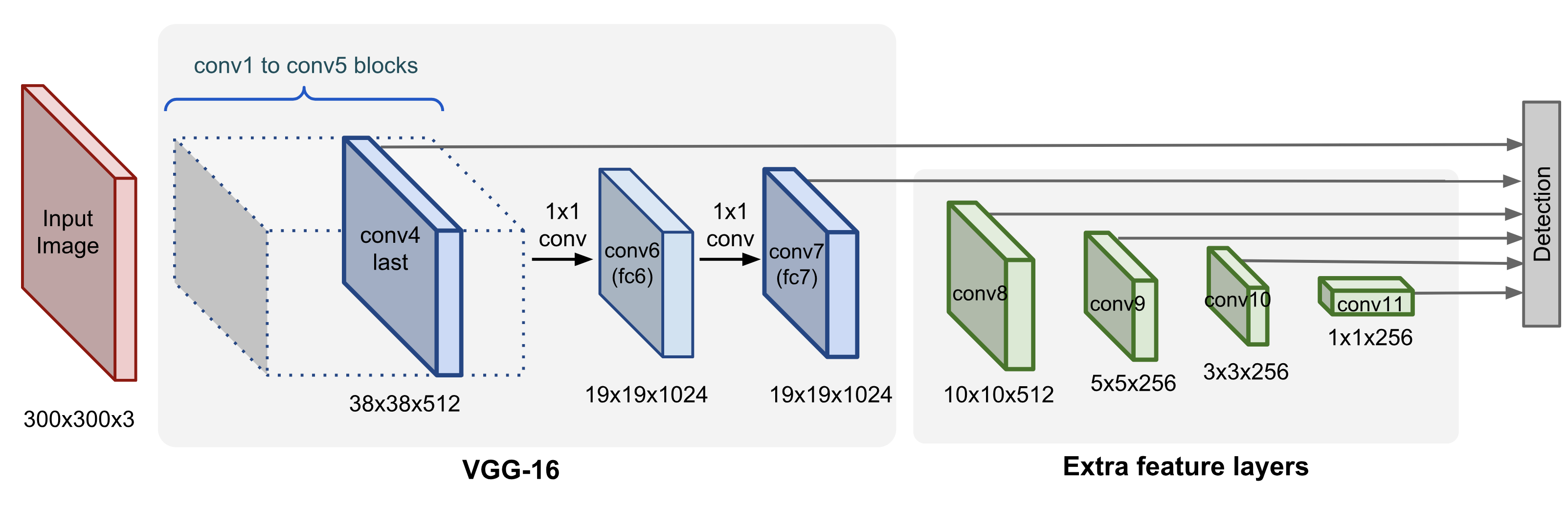
SSD的网络结构 (Source: Lilian Weng's blog post)
Workflow
- 在大型数据集(例如ImageNet)上用图像分类任务预训练一个CNN网络。
- 在提取到的各个尺度的feature maps中,SSD在各个cell上预测目标相对于预定义的anchor boxes的偏移(与YOLO在各个cell上预测任意位置的bounding boxes不同)。每个cell都有一系列预定义的anchor boxes,每个anchor box相对于其所属的cell有固定的位置与大小所有的anchor boxes能够铺平整个feature map。
由于不同层的feature maps有不同的感受野,其中的anchor boxes被缩放到一定的大小,使得一个feature map只负责一种尺寸的目标检测。
在每个cell的$k$个anchor boxes上,SSD使用$3\times 3 \times p$的卷积来预测位置的4个offset与$c$个类别概率,也就是说,对于一张$m\times n$的feature map,总计产生$k\times m \times n \times (4+c)$个预测值。
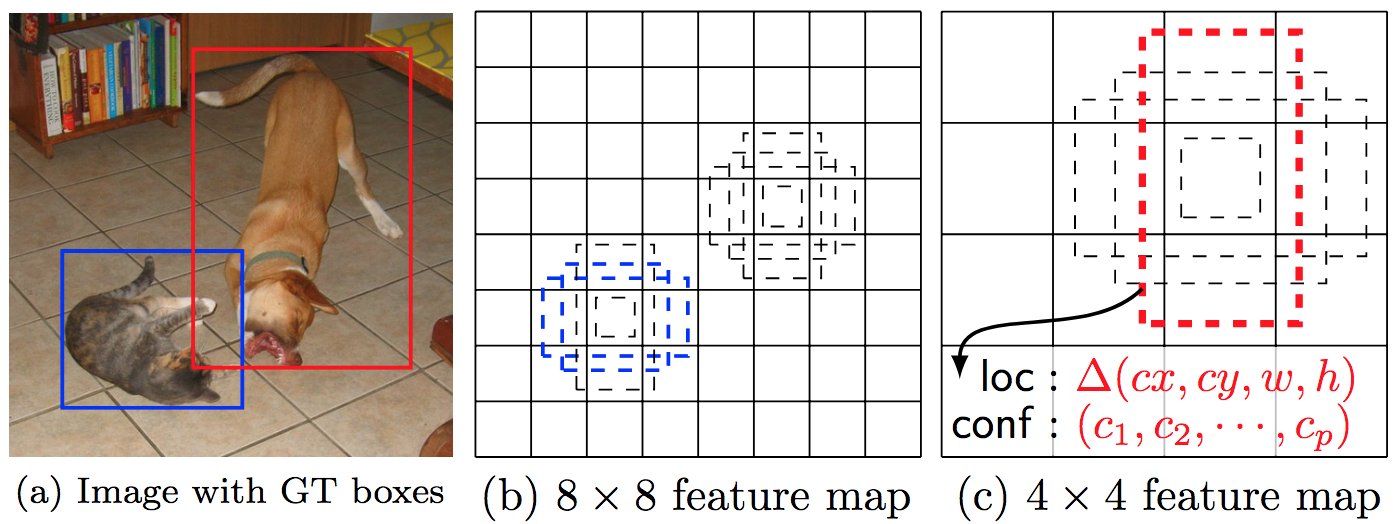
SSD检测示意图,不同尺寸的feature map负责不同尺度的目标检测。可以看出,狗只能在$4\times 4$这样粗粒度的feature map中被检测到,而猫只能在$8\times 8$这样细粒度的feature map中被检测到。 (Source: original paper)
Details
Choosing scales and aspect ratios for default boxes
在$m\times n$大小的第$\ell$层feature map的第$(i,j)$个cell上,可以根据层级$l$定义一个线性缩放比例$s_\ell$以及5个基本的anchor box纵横比$r$,以及1个当$r=1$时与层级$l$有关的特殊缩放因子$s’_\ell$,也就是每个cell预定义了6个不同大小的anchor boxes。每个anchor box的$(x,y,w,h)$均经过了归一化。
- 层级$\ell \in [1,L]$,其空间尺寸为$n\times m$
- Cell位置$(i,j) \text{ where }i \in [1,n], j \in [1,m]$
- anchor box缩放因子
$s_\ell = s_\text{min} + \frac{s_\text{max} - s_\text{min}}{L - 1} (\ell - 1)$ - anchor box纵横比
$r = \{1, 2, 3, 1 / 2, 1 / 3\}$ - anchor box特殊缩放因子
$s'_\ell = \sqrt{s_\ell s_{\ell + 1}} \text{ when } r = 1$ - anchor box宽度
$w_\ell^r = s_\ell \sqrt{r}$ - anchor box高度
$h_\ell^r = s_\ell / \sqrt{r}$ - anchor box中心点坐标
$(x^i_\ell, y^j_\ell) = (\frac{i+0.5}{m}, \frac{j+0.5}{n})$
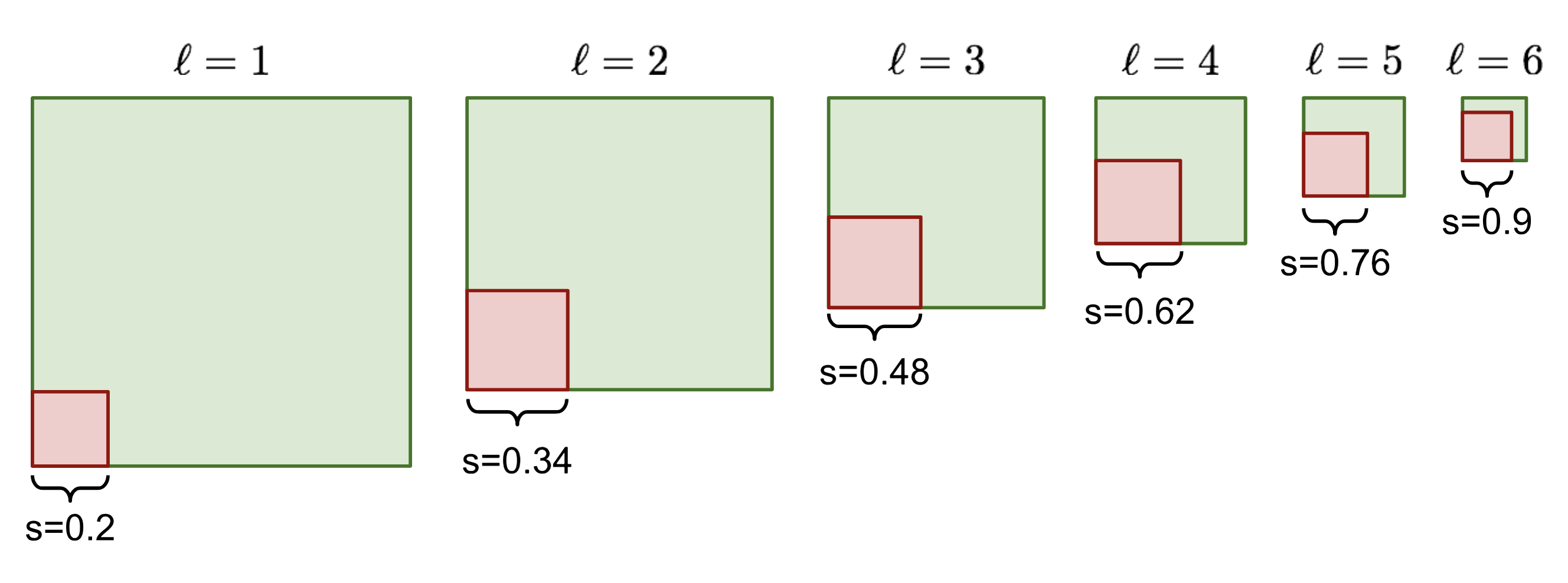
SSD缩放anchor box示意图。图中只显示了$r=1$的anchor box,取$L=6, s_\text{min}=0.2, s_\text{max}=0.9$ (Source: original paper)
Loss Function
同YOLO类似,SSD的损失函数也由定位损失与分类损失两者组成:
其中$1 / N$为匹配成功的bounding boxes数量,$\alpha$为平衡两个损失的系数,由交叉验证来确定其值。
- SSD的定位损失使用的是Smooth L1 Loss,坐标变换使用的是R-CNN的bounding box回归中的方法。其中
$\mathbb{1}_{ij}^\text{match} $表示第$i$个预测的bounding box$(p^i_x, p^i_y, p^i_w, p^i_h)$是否与第$j$个真值$(g^j_x, g^j_y, g^j_w, g^j_h)$在位置上相匹配。$d^i_m, m\in\{x, y, w, h\}$为预测值的校正项。
- SSD的分类损失使用了多类别的softmax函数。其中
$\mathbb{1}_{ij}^k \log(\hat{c}_i^k)$表示第$i$个bounding box是否与第$j$个真值是否在类别$k$上相匹配。$pos$代表了与真值匹配上的bounding boxes,$neg$则表示其他的负样本。
Matching Strategy
与YOLO只将与某一个ground truth拥有最高IoU的预测bounding box视为匹配的做法不同,SSD将anchor boxes与所有IoU超过阈值的ground truth进行匹配。文章宣称,这种做法能够使网络对多个有重叠的anchor boxes都给出高置信度,而不是只对其中一个具有最高IoU的给高置信度。
Hard Negative Mining
SSD同时也使用了与R-CNN类似的hard negative examples来使用容易被误分类的负样本构建$neg$集合。最终用以训练的正负样本比例大约在$1:3$左右。这种方法能够是模型快速收敛,并且提升训练的稳定性。
Data argumentation
SSD在数据扩增方面主要使用了random crop来时的模型能够对不同尺寸与性状的输入更为鲁棒。其输入图像为:
- 整张原始尺寸的输入图像
- 随机裁剪后的与目标有一定IoU(如$0.1$,$0.3$,$0.5$,$0.7$,$0.9$等)的patch
- 完全随机裁剪后的patch
这些随机裁剪的大小为$[0.1,1]$的原始尺寸以及$[1 / 2, 2]$的纵横比。如果ground truth的中心在patch中,则保留之。
此外,SSD还使用了概率为$0.5$的随机水平翻转。
Tricks
Smooth L1 Loss
- 相比于L2 Loss,Smooth L1 Loss对于离群值更不敏感,离群值不会占据损失的主要部分,避免梯度出现大的波动;
- 相比于L1 Loss,Smooth L1 Loss在$0$处有唯一导数,不会影响到收敛。
Atrous Convolution
SSD在conv6与conv7层中使用了Atrous convolution,其能够通过空洞的方式,在不增加kernel参数量的情况下,增大卷积操作的感受野。
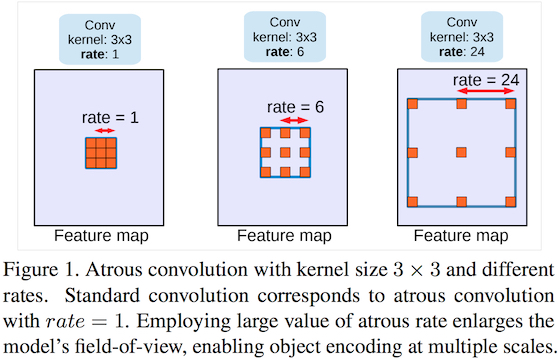
SSD中的Atrous Convolution操作(Source: DeeplabV3)
Deduction
- 使用上文所述的数据扩增方法能显著改善mAP
- 使用更多的feature maps能改善mAP
- 使用更多的anchor box性状可以改善mAP
- 使用Atrous卷积版本VGG-16可以改善mAP并提高速度
Drawbacks
YOLOv2
YOLOv2是原版YOLO的改进版本,YOLO9000则在YOLOv2的基础上使用了COCO数据集进行训练,并且使用了ImageNet中的9000个类别。
Improvements of YOLOv2
Batch Normalization
在所有卷积层之后增加了BN层,对于收敛有很大帮助,提升了2%的mAP。
High Resolution Classifier
原版YOLO使用$224\times 224$的分辨率来预训练分类网络,而后将分辨率提升到$448\times 448$来训练检测网络。这使得网络既要从分类任务切换到检测任务,又要适应新的分辨率。YOLOv2则在训练检测任务之前,先将$224\times 224$的网络以$448\times 448$的分辨率在ImageNet上进行10个epoch的分类任务fine-tuning,让网络有时间来调整filters来适应新的分辨率。在这之后,再进行检测任务的fine-tuning,这样能够提升4%的mAP。
Convolutional With Anchor Boxes
YOLOv2放弃了用FC层在整个feature map上预测bounding boxes的位置,转而同Faster-RCNN一样,使用卷积层来预测anchor boxes的位置offset,以此来简化问题,并且使网络更容易学习。
为此,YOLOv2针对网络结构作出了以下改动:
- 去掉了一个pooling层,提升了最后一层卷积层输出的尺寸。
- 为了让图像中心只有一个cell,把输入尺寸从$448\times 448$改成了$416\times 416$。中心只有1个cell而不是4个的好处在于,图像中的大物体的中心通常都会落在图像的中心上,预测的时候从1个cell出发预测位置较好一些。
- 最终feature map的cell数量为$13\times 13$。
与此同时,YOLOv2将类别预测与空间位置解耦了,不再由cell统一预测其内bounding boxes的类别,而是对每个anchor box都进行单独的预测。
作出这些更改后,YOLOv2所预测的boxes数量从原先的98个一跃上升到了超过一千个。这使得mAP有略微下降(69.5 vs 69.2),但是召回率有很大提升(81% vs 88%)。
Dimension Clusters
为了让模型能够更快地学习到如何做出好的检测,YOLOv2没有像Faster R-CNN和SSD那样,手动设定anchor box dimension的prior,而是在训练集上使用了k-means聚类来获取prior。同时,为了避免anchor box的大小对于聚类距离的影响,使用IoU来计算距离:
经过实验发现,取$k=5$是一个比较好的对recall与complexity的trade-off,此时在平均IoU上已经与hand-picked的9个anchor boxes相差无几。同时,VOC与COCO数据集上的聚类结果都表明,anchor box更加偏向于thinner and taller的,而且COCO上的比VOC上的要大一些。
Direct location prediction
引入anchor box的另一个问题是模型训练在早期的不稳定性,这主要是由于预测$(b_x,b_y)$的不稳定性,这一不稳定性又来源于其预测位置的机制。RPN通过预测anchor box $(x_a, y_a, w_a, h_a)$的偏移值$(t_x, t_y)$来计算$(b_x,b_y)$:
这样会使得极端情况($t_x = 1$或$t_x = -1$)下,预测的bounding box会整个偏移anchor box的宽度。如此一来,任何anchor box能够不管其所属的cell在哪,都能够偏移到图像的任何位置上,这显然是不可接受的。这种预测位置的任意性使得网络训练初期并不稳定。
为了让预测的bounding box尽可能地约束在其所属的grid cell内,YOLOv2还是采用了原版YOLO的方法,使用logistic activation来约束偏移量在$[0,1]$内。
其中,$(t_x, t_y, t_w, t_h, t_o)$为网络对每个bounding box的5个预测值,$(p_w, p_h)$为anchor box的宽高,$(c_x, c_y)$为anchor box所配属的grid cell的左上顶点的坐标。在训练时,ground truth也可以由上式得到,误差依然采用SSE (Sum Squared Error)来计算。
使用direct location prediction与dimension clusters后,YOLOv2比直接使用anchor boxes的版本在性能上提升了5%。
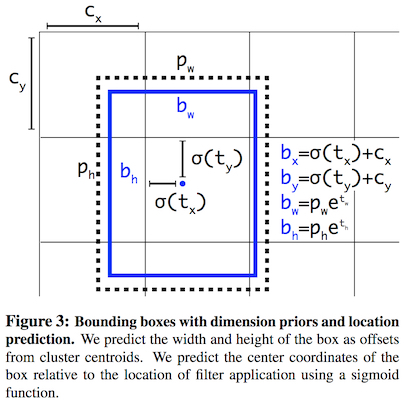
YOLOv2中的直接位置预测 (Source: original paper)
Fine-Grained Features
不同于Faster R-CNN与SSD那样在不同尺寸的feature map上分别做检测,YOLOv2增加了一层passthrough层,将之前的$26\times 26$的细粒度的feature map引入到最终输出的$13\times 13$的feature map中去。具体地说,类似于ResNet的Identity Mapping,YOLOv2直接将之前的层的输出($26\times 26 \times 512$的feature map)中邻近的特征从空间位置堆叠到了channel上,变成了$13\times 13 \times 2048$大小的feature map。然后,将这一feature连接到最后一层的输出上。这一方法提升了1%的性能。
Multi-Scale Training
由于YOLOv2采用了全卷积的结构,其网络输入的尺寸可以缩放。为了让网络对于多尺度的目标都能够检测,YOLOv2每10个epoch就会改变输入尺寸。由于网络从输入到输出降采样了32倍,所以输入尺寸的选择为$\{320,352,\ldots,608\}$。更小的输入尺寸意味着更快的速度,$228\times 228$的YOLOv2在精度上能与Fast R-CNN不相上下,而速度则达到了90FPS;而$544\times 544$的YOLOv2则能够在PASCAL VOC 2007数据集上达到78.6的mAP。
Light-weight base model
为了进一步提升网络预测速度,YOLOv2将其基础网络换成了Darknet-19,由19层卷积层与5层max-pooling层组成。
- 类似于VGG,使用$3\times 3$卷积,在pooling层之后倍增channels数量
- 类似于NIN (Network In Network),在$3\times 3$卷积之间使用$1\times 1$卷积来压缩特征表示,并且使用global average pooling来做预测
YOLO9000
由于image-level的标签比box-level的标签更加容易获取与标注,该文章提出了一种将小型目标检测数据集与大型的分类数据集(如ImageNet)联合训练的方法,使得检测模型能够使用ImageNet上的大量类别。YOLO9000的名字就是从ImageNet中的前9000个类别中来的。
两个数据集的label通常不互斥,而且目标检测数据集的labels一般更为宽泛,比如ImageNet上有”Persian cat”的label,而COCO数据集上只有”cat”的label。所以直接使用softmax是没有任何意义的。为了更有效地整合ImageNet的1000个细分类的labels以及COCO/PASCAL的少于100个的粗分类的labels,YOLO9000使用了类似WordNet的树结构。宽泛、粗分类的labels更加靠近根节点,细分类的labels则为叶节点,比如说”Persian car”就是“cat”的子节点。
此时,类别的概率的计算沿着某一类别的节点到根节点的路径进行:
- 在联合训练中,如果输入图像来自于图像分类数据集,则只计算并反传分类损失。即找到属于该类别的置信度最高的bounding box来计算。同时,分类损失只反传到其本身以及之上的类别,其下的细分类别不反传。
- 为了平衡数据样本数量,通过过采样COCO数据集,使得来自ImageNet的样本(9418类)出现概率仅为COCO的4倍
- 使用$k=3$的prior来减少输出的大小
RetinaNet
Focal Loss
目标检测的一大难题是,没有物体的背景与有物体的前景之间极端的数量不平衡的问题。RetinaNet提出了Focal Loss来给难以训练、容易误分类的样本(例如拥有复杂纹理的背景或者只包含了部分物体的样本)更高的权重,而给那些容易的样本(如完全空无物体的背景)更低的权重。
二分类问题的交叉熵损失定义如下:
其中$y\in\{0,1\}$表示该bounding box是否包含物体的ground truth label,$p\in[0,1]$则表示预测是否有物体的置信度。
令
则有
容易分类的样本一般具有较高的物体置信度,$p_t \gg 0.5$。也就是说当$y=0$时,$p \to 0$;当$y=1$时,$p \to 1$。这可能会导致loss出现非平凡的量级。Focal Loss在交叉熵损失中显式地增加了一个权重因子$(1-p_t)^\gamma, \gamma \geq 0$,使得当$p_t$变大时,该权重会减小,从而使得容易样本被降权。
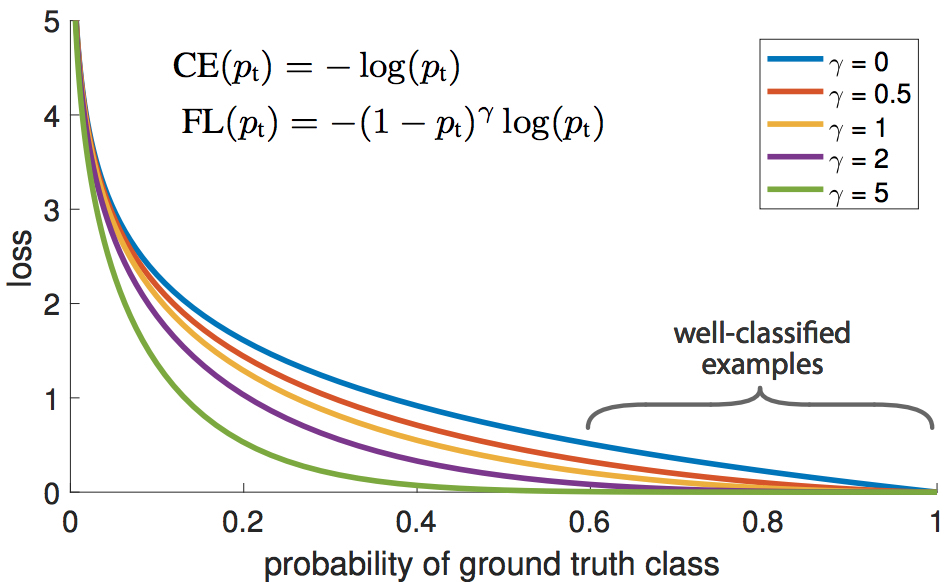
Focal Loss与原始交叉熵损失 (Source: original paper)
此外,为了更好的控制权重函数的形状,Focal Loss还加了一个系数$\alpha$来平衡。一般取$\alpha=0.25, \gamma =2$。
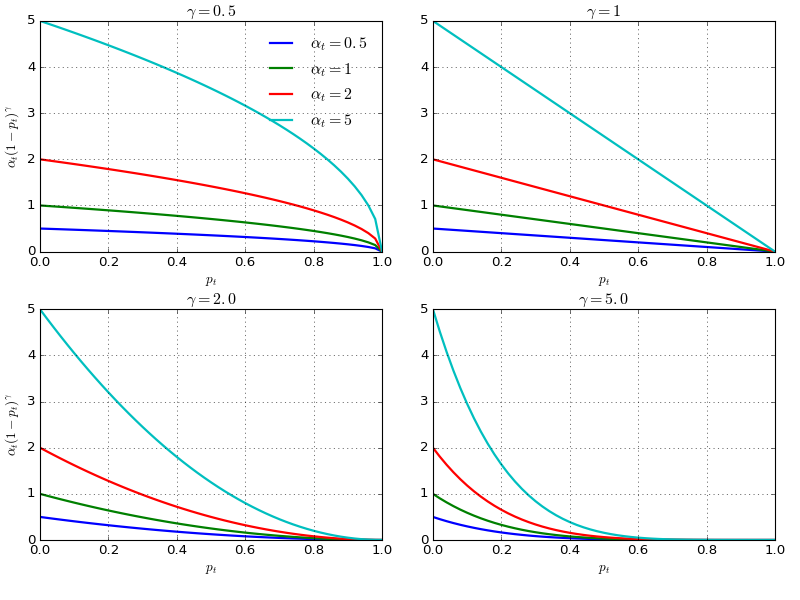
不同$\alpha$与$\gamma$下的Focal Loss (Source: Lilian Weng's blog post)
Featureized Image Pyrmaid
RetinaNet还采用了
(W.I.P.)
YOLOv3
正如其标题所说,YOLOv3是一个增加了大量tricks的增量更新的版本。相比于YOLOv2,YOLOv3精度更高、鲁棒性更强,但是为此在速度上做出了一定的妥协。
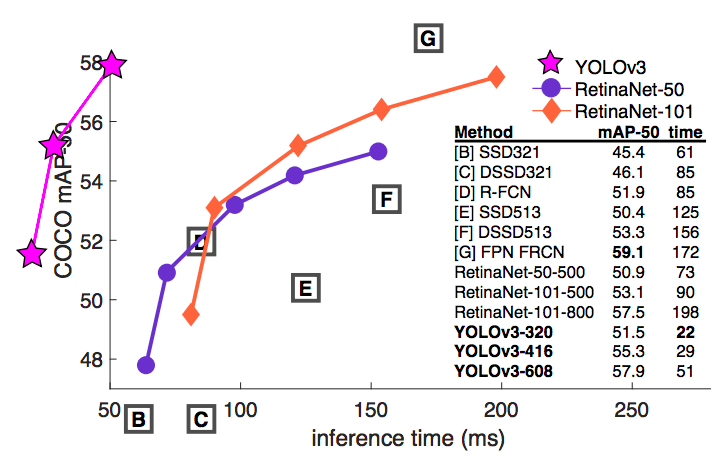
YOLOv3性能 (Source: Ayoosh Kathuria‘s blog post)
Improvements
Logistic regression for confidence scores
YOLOv3使用logistic regression来预测每个bounding box的objectness score。也就是说,在YOLOv1与YOLOv2的loss function的基础上,将分类损失$\mathcal{L}_\text{cls}$的度量由SSE变成了交叉熵。
No more softmax for class prediction
YOLOv1与YOLOv2是使用softmax来处理类别预测,而后从中找出最大的得分作为该bounding box的类别。这么做有一个问题,softmax是假设所有的类别都是互斥的且每个目标只属于单个类别,这在COCO数据集上没问题,但是如果数据集上包含了不互斥的lables(如Open Images Dataset中的Person与Women),那就不行了。
YOLO9000给出的答案是使用WordNet那样的层级label结构,而YOLOv3则使用不同的逻辑回归器与阈值来预测不同个类别。训练时,则使用二值的交叉熵损失来衡量。如此一来,YOLOv3对于单目标多标签的问题也能解决。
Darknet + ResNet as the base model
YOLOv3将residual block引入了Darknet,提出了新的Darknet-53基础网络。在Darknet-53的基础上,YOLOv3为了检测任务又增加了53层,总计达到了106层。整个网络引入了许多新的已经被其他方法证明行之有效的模块,比如residual blocks、skip-connections以及upsampling。这也是YOLOv3比YOLOv2略慢的原因。
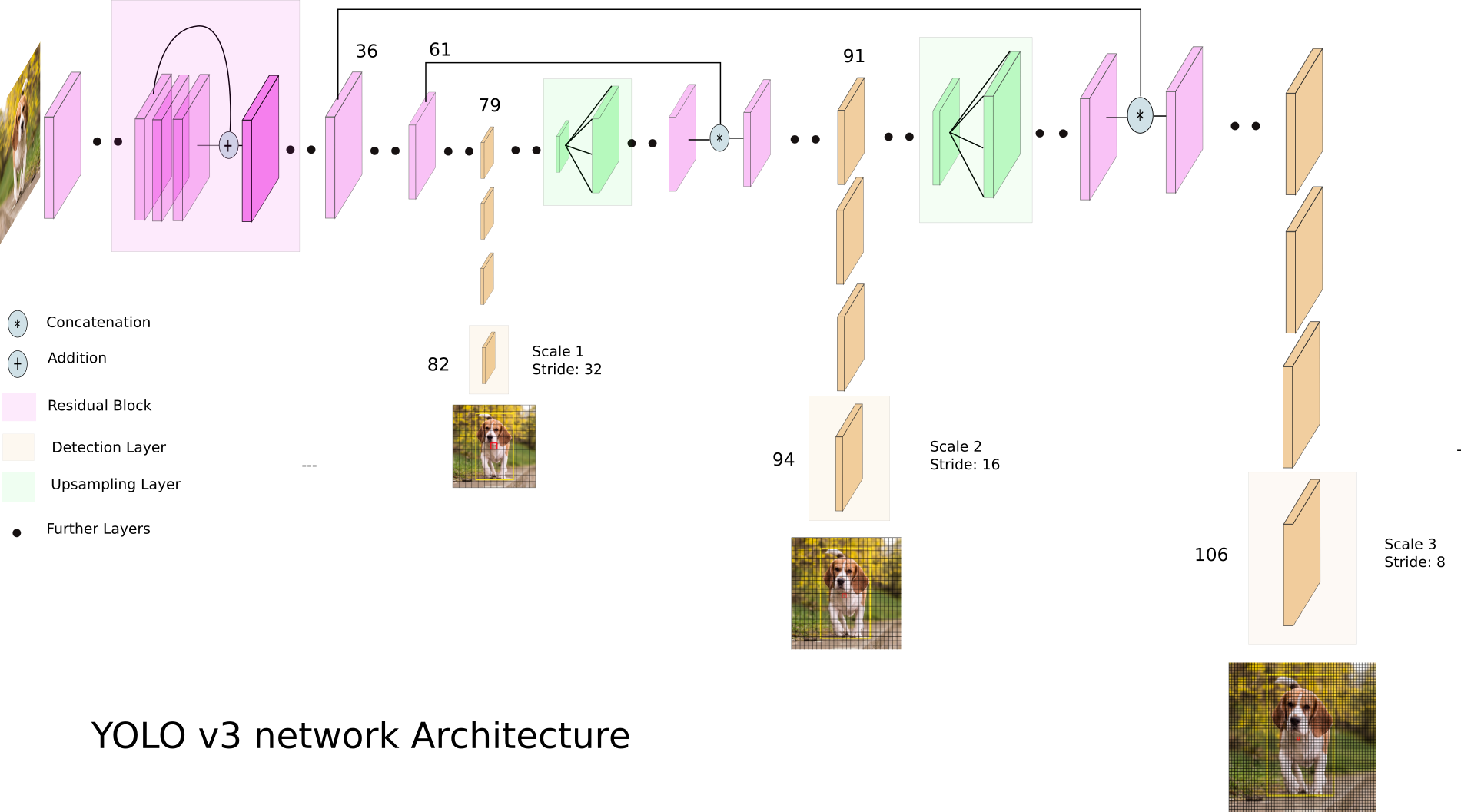
YOLOv3网络结构 (Source: Ayoosh Kathuria‘s blog post)
Multi-scale prediction
YOLOv3最为显著的改进就是其使用3种不同尺度进行检测。不同于YOLOv2只是将之前层的输出concat到最后一层上,YOLOv3直接用$1\times 1$卷积在三种不同尺度的feature maps上做检测。
具体地说,假设输入尺寸为$416\times 416$,YOLOv3的检测在3个尺度展开:
- 82层:尺寸$13\times 13$,缩小$32$倍,用以检测大物体
- 94层:尺寸$26\times 26$,缩小$16$,用以检测中等大小的物体
- $106$层(尺寸$52\times 52$,缩小$8$倍,用以检测小物体
在每一层都有三种anchor boxes,总计有9种anchor boxes。卷积核的大小为$1\times 1 \times (B \times(5+C))$,即每个cell上预测$B$个bounding box,每个bounding box含有4个位置信息、1个物体是否存在的置信度以及$C$类的类别概率。
这种多尺度的预测,使得YOLOv3在每张图像上预测的bounding boxes数量远远多于YOLOv2。
- YOLOv2只在最后一层进行预测,每个cell预测5个bounding boxes,总计$13\times 13 \times 5 = 845$个
- YOLOv3在三个尺度进行预测,每个cell预测3个bounding boxes,总计$(13^2+26^2+52^2)\times 3=10647$个

YOLOv3多尺度检测 (Source: Ayoosh Kathuria‘s blog post)
Skip-layer concatenation
同样地,YOLOv3在两个尺度的检测之间增加了跨层的连接,后面的层通过Upsample层扩大尺寸与前面的层在通道上进行concat。这样能够提升对小物体的检测性能。
Failed Cases
Anchor box $x,y$ offset predictions
直接预测anchor box的实际$(x,y)$偏移(相当于已经乘上了$w$与$h$),这样会降低模型稳定性。
Linear $x,y$ predictions instead of logistic
直接使用线性回归而不是logistic回归来预测$(x,y)$偏移,会使mAP下降好几个点。
Focal Loss
作者尝试在YOLOv3中引入Focal Loss,但是反而使得mAP降低了2%。其推测的原因是YOLOv3已经将objectness predictions与conditional class predictions分开了,所以对于focal loss想要解决的问题,YOLOv3已经足够鲁棒了,不需要再额外增加focal loss。
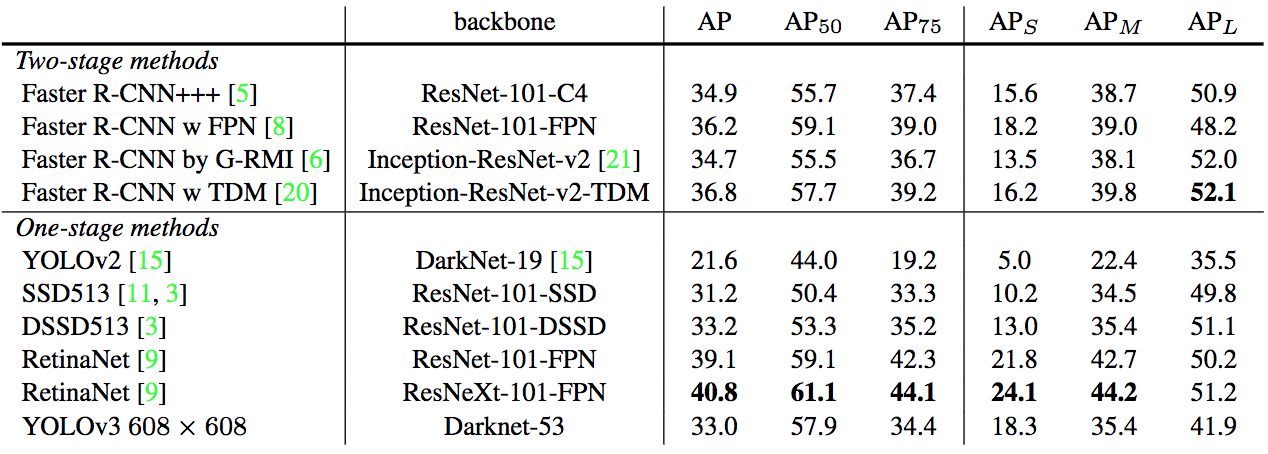
Benchmark
在COCO数据集上,如果采用更加严格的IoU overlap限制(如$\text{AP}_75$),则YOLOv3在性能上就比不过RetinaNet。这是因为更加严格的IoU overlap限制,要求预测的bounding boxes与ground truth在对齐上做得更好。如果IoU低于限制的阈值,则被视为是定位错误,并被标记为false positive,然后被reject掉。YOLOv3在这一点上比不过RetinaNet。