Notes for YOLO
Contents
前几天发烧流鼻涕, 睡不了觉, 因此就熬夜读完了 YOLO 的论文. 可以说, YOLO 的实现方式相较于之前 R-CNN 一系的 Region Proposal 的方法来说, 很有新意. YOLO 将 Classification 和 Bounding Box Regression 合起来放进了 CNN 的输出层里面, 从而大大加快了速度.
Unified Detection
YOLO 将 Bounding Box 的位置回归和分类都放在了 CNN 的输出层中, 从整张图输入来预测 Bounding Box 的信息, 从而实现了 end-to-end 的训练, 实时的检测性能, 并且还保持了较高的精度.
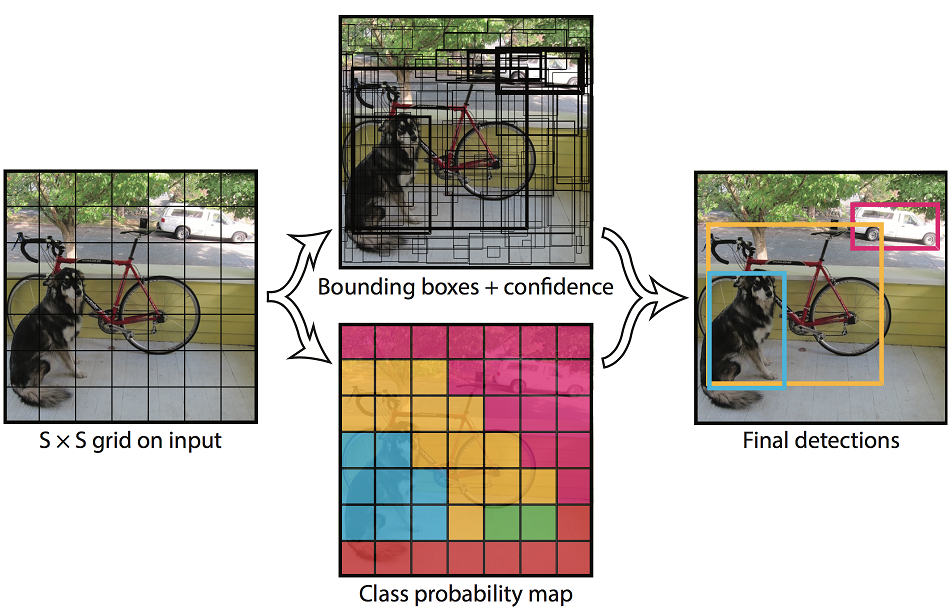
YOLO 将整张图分成了S×S个网格 (论文中S=2), 如果一个物体的中心在某个网格内, 那么这个网格就负责预测这个物体的检测.
每个网格需要预测B个 Bounding Box (论文中B=2), 以及它们的置信度 (confidence).
- 置信度定义为Pr(Object)∗IOUtruthpred
- Pr(Object) 即为有物体的概率, 取0或1
- IOUtruthpred 即为 ground truth 与predicted box 区域的交并比
- 每个 Bounding Box 有5个属性(x,y,w,h,c)
- (x,y) 代表 Bounding Box 的中心距离与网格边界的相对距离, 取值在0与1之间
- x=xmax+xmin2∗width
- y=ymax+ymin2∗height
- (w,h) 代表 Bounding Box 的长宽与整个图像长宽的相对比值, 取值在0与1之间
- x=xmax−xminwidth
- y=ymax−yminheight
- c 即此 Bounding Box 的置信度
每个格子还要预测 C 个类别的概率, 记为Pr(Classi|Object). 此概率与网格中是否有物体有关, 并且使相对于每个网格来说的, 与网格中的 Bounding Box 数量 B 无关.
- 测试时, 将 class 的条件概率和 box 的置信度乘起来, 得到每个 box 关于 class 的置信度
- Pr(Classi|Object)∗Pr(Object)∗IOUtruthpred=Pr(Classi)∗IOUtruthpred
- 这个概率既包含了 box 属于哪个 class 的概率, 又包含了这个 box 对于 object 的拟合度
合起来看, 最终的预测张量的维数是 S×S×(B∗5+C). 论文里用 PASCAL VOC 数据集, 取S=7,B=2,C=20, 因此总计7×7×30.
Network Design
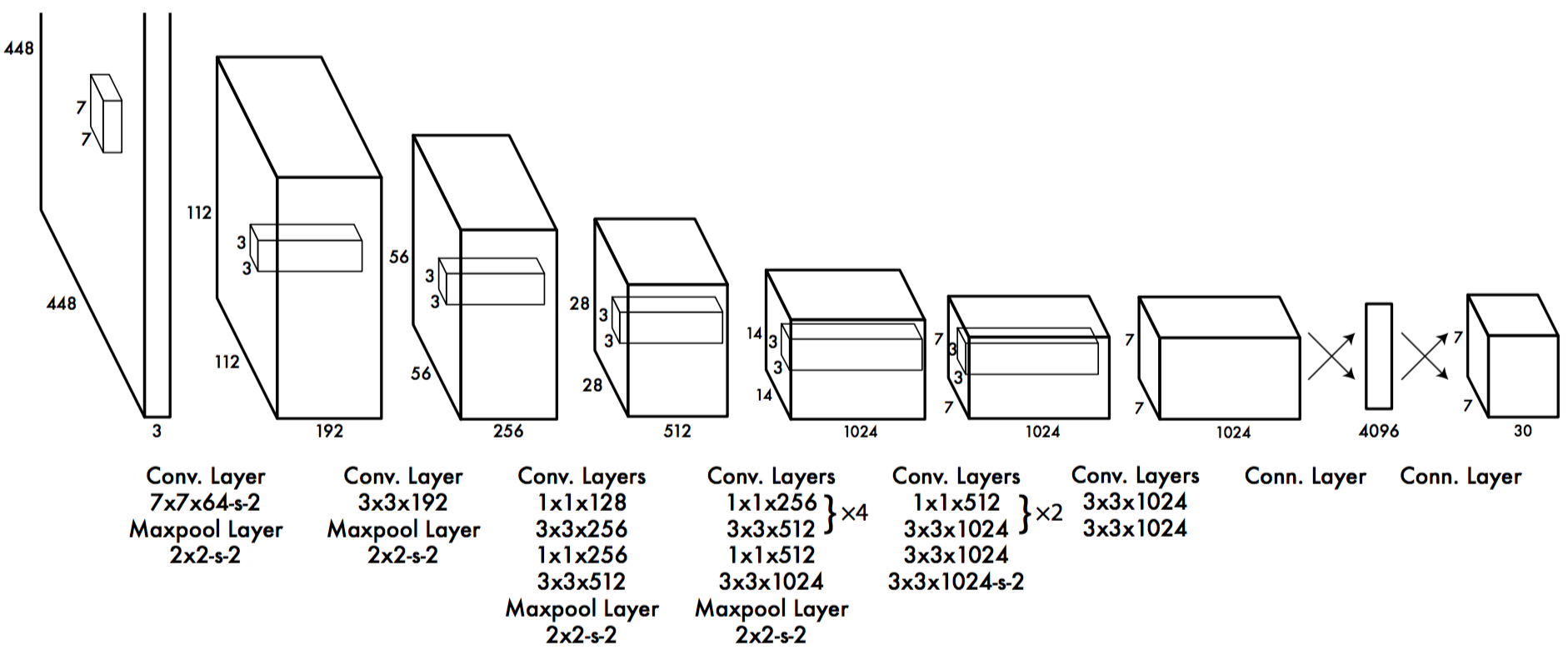
整个网络参考了 GoogleNet, 总共有24个卷积层和两个全连接层.
Training
为了让整个网络有更好的性能, YOLO 使用了以下 tricks:
前20层卷积层使用 ImageNet 进行 pretrain, 后4层卷积层和两层全连接层则是随机初始化
将输入图像的分辨率从224×224提升到448∗448
将(x,y,w,h)全部都归一化 (详见上文)
最后一层(输出层)采用线性激活函数, 其它层都用 Leaky ReLU.
损失函数采用平方和误差(sum-squared error), 并且针对以下问题作出了改进:
- 8维的 box 的位置信息(x,y,w,h), 2维的置信度信息, 以及20维 box 的类别信息的平方和误差直接放在一起显然是不合理的. 因此增加 box 的位置信息的误差的权重系数λcoord (论文内取5).
- 同时, 一个图像会有很多网格没有物体, 那么就会把格子里的 box 的置信度变成 0, 导致那些真正有物体的柜子被压制, 最终导致整个网络发散.因此减少没有物体的 box 的权重系数λnoobj (论文内取0.5).
- 另外, 平方和误差会把 large box 和 small Box 的误差一视同仁. 然而相对于 large box 稍微偏一点, small box 的误差更加不能忍受. 因此使用(√w,√h)而非(w,h)来计算误差.
- 每个格子里都有多个 Bounding Box, 但是在训练的时候我们希望对于每个物体只有一个 Bounding Box Predictor. 因此就选择与 ground truth 的 IoU 最大的那个, 称对该 box 对 该 object “负责” (responsible).
最终整个的 loss function 如下:
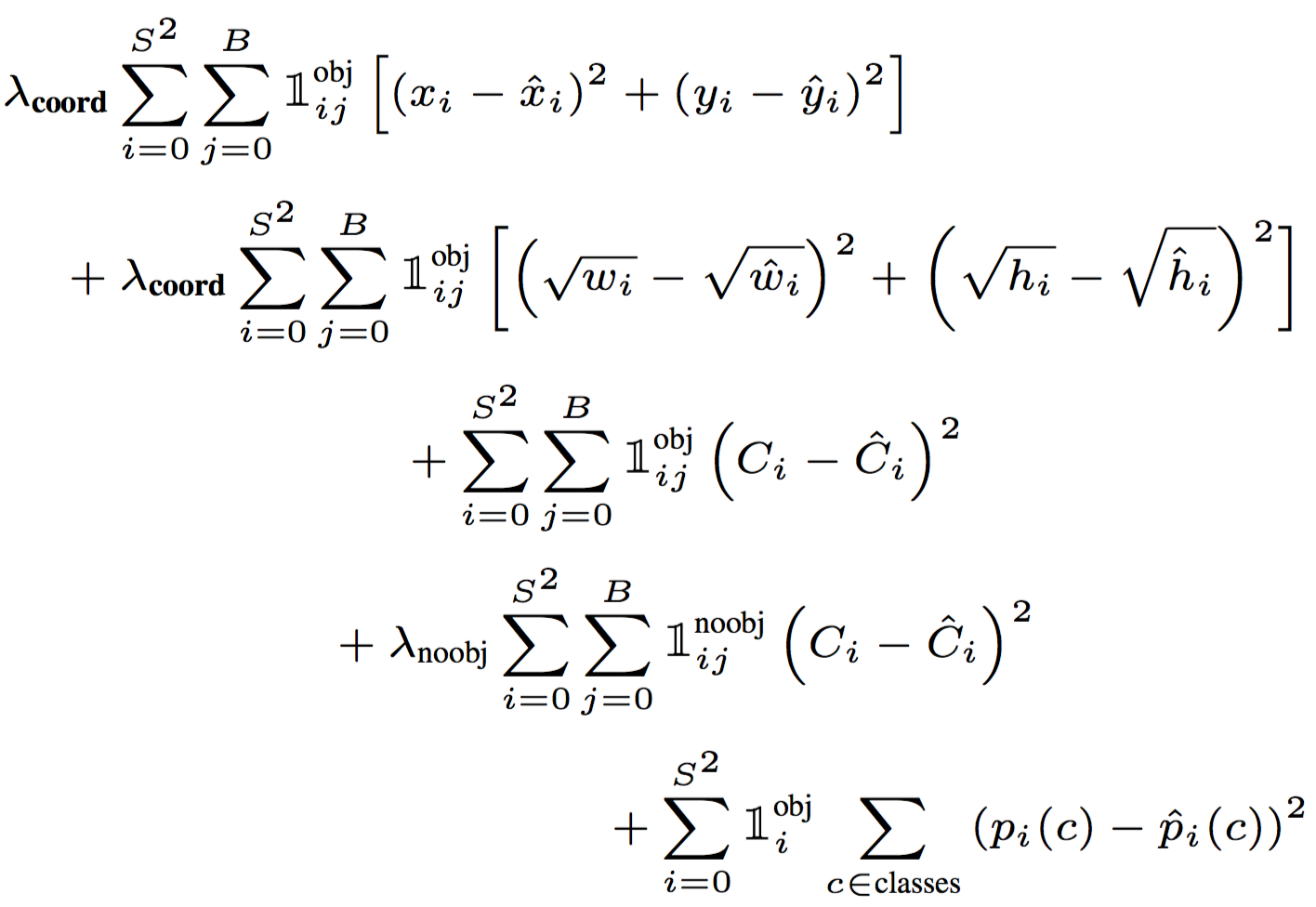
- 1objij代表第i个网格中的第j个 box 是否对此 object “负责”, 1obji表示第i个网格中是否有 object.
该损失函数仅仅对有物体的网格的分类误差, 以及对 ground truth box 负责的 box 的位置误差进行惩罚
另外还采用了 Dropout 和 Data Augmentation 的方法来增强泛化能力.
- Dropout=0.5
- 对图像进行最大20%的随机缩放和平移变换, 同时还有最大1.5的曝光与色调变换
Limitations of YOLO
- 由于 YOLO 每个网格只有 B 个Bounding Box与1个 Class, 因此限制了临近物体检测到的个数
- 泛化能力不够, 由于降采样比较多导致只能用比较粗的特征
- 损失函数主要来源还是定位误差, 在对大小物体的位置误差的均衡上还需要改进.