Notes for ScribbleSup
Contents
毕设需要写一个图像标注的软件, 来给场景分割的数据集做标注. 经学长推荐, 看了今年的这篇文章, 作者中竟然还有 Kaiming He 大神, 给微软膜一秒.
这篇文章讲了一个弱监督的场景分割的算法 ScribbleSup, 主要是先通过 Graph Cut 将输入的 scribble 信息广播到没有标注的像素, 然后用 FCN 来做像素级别的预测. 令人遗憾的是 Github 上并没有人实现 (不能偷懒了TAT).
Introduction
TBD
Scribble-Supervised Learning
Objective Functions
主要用到的记号如下:
| Symbol | Name | Note |
|---|---|---|
| $X$ | training image | |
| ${x_i}$ | set of non-overlapping superpixles | $\cup_i x_i = X; x_i \cap x_j = \varnothing, \forall i,j$ |
| $S$ | scribble annotations of image | $S={s_k, c_k}$ |
| $s_k$ | the pixels of a scribble $k$ | |
| $c_k$ | the scribble’s category label | $0 \le c_k \le C$; $c_k=0$ for background |
| $Y$ or ${y_i}$ | the category label of ${x_i}$ | provides full annotations of the image |
定义目标函数为
$$\sum_i \psi_i (y_i | X,S) + \sum_{i,j} \psi_{ij} (y_i, y_j | X)$$
其中$\psi_i$是一个关于$x_i$的一元项 (unary term), 而$\psi\ _{ij}$是关于$x_i$与$x_j$的成对项 (pairwise term).
$\psi _i$由两个部分组成, 一个是$\psi ^{scr}_i$, 另一个是$\psi^{net}_i$.两者权重相同, $\psi _i = \psi^{scr} _i + \psi^{net} _i$.
$\psi ^{scr}_i$ 基于 scribble, 定义如下: $$ \psi ^{scr}_i= \begin{aligned} &0 & \text{if $y_i=c_k$ and $x_i \cap s_k \ne \varnothing$}\
&-log(\frac{1}{|c_k|}) & \text{if $y_i \in {c_k}$ and $x_i \cap S = \varnothing$} \
&\infty & \text{otherwise} \
\end{aligned} $$当$x_i$与$s_k$有交集, 且标签是分到$c_k$时, 则$cost=0$
当$x_i$与所有 scribble 都没有交集, 则它可以被等概率地分给任何标签. 当然, $y_i$需要在${c_k}$之内. 此处$|{c_k}|$表示标签集内元素个数.
如果不是以上两种情况, 则$cost= \infty$
$\psi ^{net}_i$基于 FCN 的输出, 定义为 $$ \psi^{net}_i (y_i) = -log P(y_i|X, \Theta) $$
$\Theta$表示网络的参数
$log P(y_i|X, \Theta)$表示了$x_i$属于标签$y_i$的对数概率, 实际上是$x_i$内所有像素的对数概率之和.
$\psi_{ij}$用以衡量相邻的两个超像素的相似程度, 主要是用色彩直方图与纹理直方图来量化 (均已归一化). $$ \psi_{ij} (y_i, y_j | X) = [y_i \ne y_j] exp \left( -\frac{||h_c(x_i) - h_c(x_j)||^2_2}{\delta_c^2} - \frac{||h_t(x_i) - h_t(x_j)||^2_2}{\delta_t^2} \right) $$
- $h_c(x_i)$ 表示RGB三个 channel 每个 channel 分成 25 bins 的色彩直方图
- $h_t(x_i)$ 表示横向与纵向的梯度直方图, 每个方向 10 bins
- $[\cdot]$表示一个符号函数, 条件为真则为$1$, 否则为$0$
- $\delta_c=5, \delta_t = 10$
- 对于不是同一个标签的临近超像素来说, 它们间的外观越相似, 则 cost 越大
最后把上边这些合起来, 就成了一个对于以下式子进行最优化的问题: $$ \sum_i \psi^{scr}_i (y_i |X, S) + \sum_i -log P(y_i | X, \Theta) + \sum_{i,j} \psi_{ij} (y_i, y_j | X) $$ 其中有两组变量, 一个是所有超像素的标签$Y={y_i}$, 另一个是 FCN 的参数 $\Theta$.
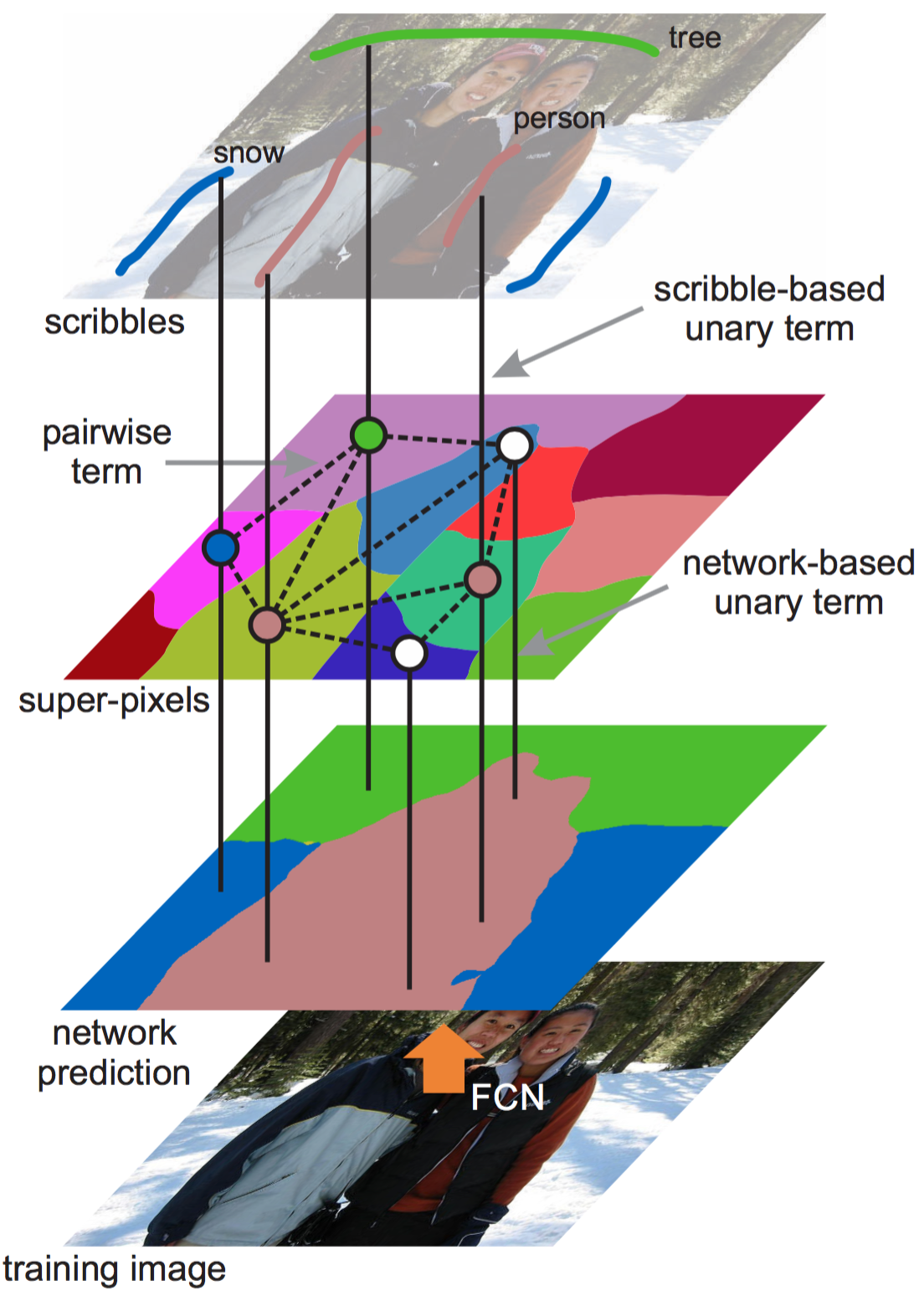
Optimization
论文里采用的是一种交替优化的方法:
- $\Theta$固定, 优化$Y$, slover 基于 scribbles, appearance 以及 FCN 网络的预测, 将标签传播到未标记的像素中
- $Y$固定, 优化$\Theta$, slover 对 pixel-wise 的语义分割的 FCN 进行学习
具体的来说就是
- Propagating scribble information to unmarked pixels
当$\Theta$固定时, 一元项$\psi _i = \psi^{scr} _i + \psi^{net} _i$能够用列举所有可能的标签$0 \le y_i \le C$得到, 成对项也能够预先计算生成一个 look-up table. 因此, 优化问题就能用 graph cut 的方法来解决. 论文里用的是这一篇文章的现成代码.
- Optimizing network parameters
前一步做完后, 所有超像素的标签都已经定好了, 也就是说$Y$固定了. 之后优化$\Theta$就相当于用$Y$做为监督来训练 FCN. $Y$有了, 那么每个像素的标签就有了, 然后 FCN 面对的就是一个 pixel-wise 的回归问题. FCN 的最后一层输出的就是每个像素的分类的对数概率, 可以用来更新 graph 上的一元项.
训练的时候有几点需要注意:
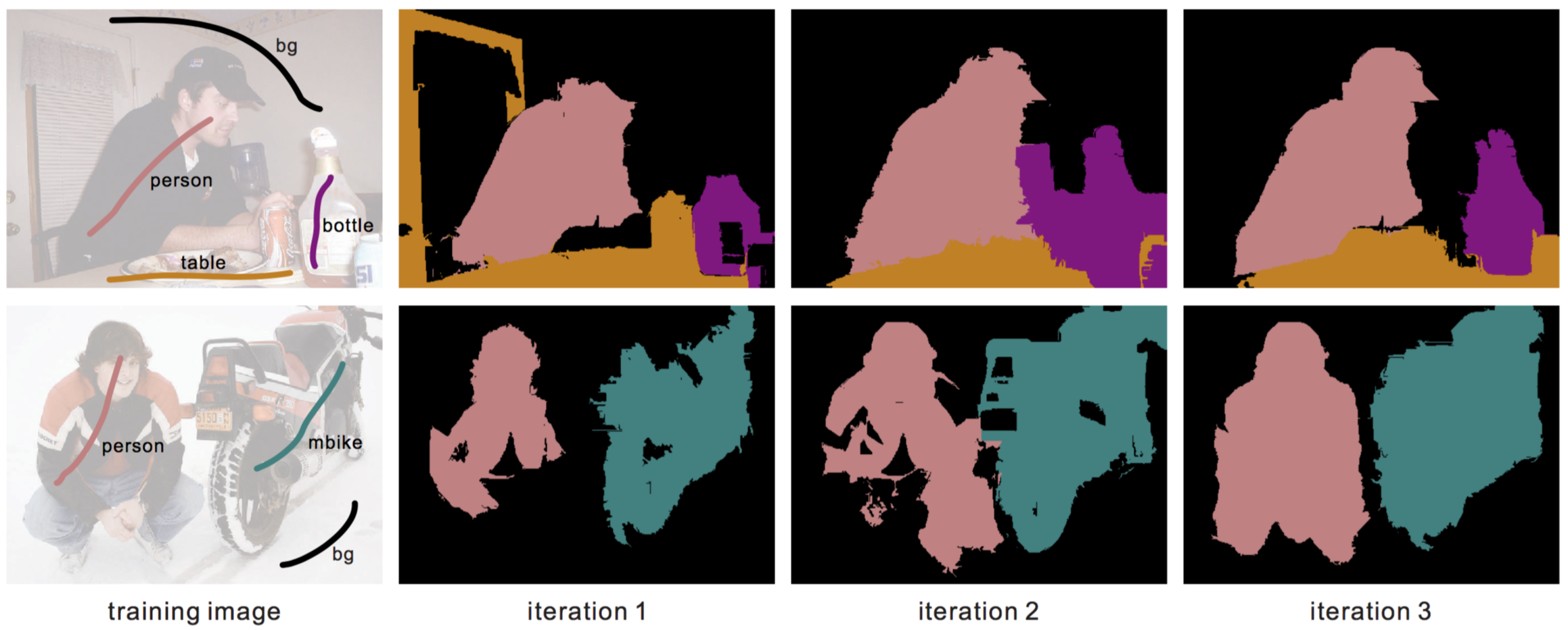
- 初始化的时候没有 network prediction, 因此就是直接用 graph cut 初始化的. 之后则是在两步之间不断迭代.
- 每次 network optimizing step 的时候, 前50k次用0.0003的 learning rate, 后10k次用0.0001的 learning rate, batch size 为 8.
- 每次 network optimizing step 都是从一个 pre-trained 的 model (比如 VGG-16) 重新初始化的. 作者也试过复用上一次迭代后的权重, 但是效果不是很理想. 似乎是由于本来标签就不可靠, 导致训练的时候参数被调到了不太好的局部最优里面.
- 基本上3次迭代就能得到比较好的效果了, 再多得到的提升微乎其微.
- 做验证的时候只要用 FCN 就好了, 超像素和 graph model 之类的都只是用来训练用的.
- Post-process 用了 CRF.
迭代结果如下:
Related Work
Graphical models for segmentation
Graphical model 在交互式的图像分割和语义分割领域是很常见的, 通常是目标函数包含了一元项和成对项, 特别适用于对局部和全局的空间约束的建模.
有趣的是, FCN 作为目前最成功的语义分割的方法之一, 由于做的是 pixel-wise 的 regression, 因此其目标函数只有一元项. 不过像 CRF/MRF 这样给 FCN 做 post-processing 或是 joint-training 的方法在之后也发展起来了.
但是这一类 graph model 都是强监督的, 主要工作是在优化 mask 的边缘, 而 ScribbleSup 里面的 graph model 主要是用来把标签传播到其他未标注的像素上. 同时, 这类方法是 pixel-based, 而 ScribbleSup 是 super-pixel-based.
Weakly-supervised semantic segmentation
用 CNN/FCN 来做弱监督的语义分割的方法很多, 用的标注方法也有很多种.
- Image-level 的标注很容易获取, 但是只用这个的话精度远低于强监督的结果
- Box-level 的相比较而言结果与强监督的接近了不少. 由于 Box annotations 本身就提供了物体边缘以及可信的背景区域的信息, 因此就不需要 graph model 来传播标签.
这些方法和本篇论文里面讲的 ScribbleSup 比起来到底哪个更胜一筹, 姿势水平更高, 就看下面的实验了.
Experiment
Annotating Scribbles
主要使用了 PASCAL VOC 2012 (20个分类) 以及 PASCAL-CONTEXT (59个分类) 这两个数据集, 同时也标注了 PASCAL VOC 2007 (标注了59个分类). 不过 2007 没有 mask-level 的标注.
总共有10个人在标注, 每张图片一人标注一人检查. 平均下来20分类的话每张图片25秒, 59分类的话每张图片50秒, 算是相当快的了.
同时, 保证每个 object 上的 scribble 至少有其 bounding box 长边的 70% 以上的长度.
Experiments on PASCAL VOC 2012
Strategies of utilizing scribbles
ScribbleSup 是将标签的扩散与网络的训练合起来考虑的, 但是一个更为简单的方案是把这两步分开来, 先用一些现成的工具 (比如说 GrabCut 或者是 LazySnapping) 把 scribble 转换成 mask, 然后再来训练 FCN 网络. 这个方案听起来也是很吼的, 那么中央到底兹不兹瓷呢, 我们来看看实验结果
| Method | mIoU(%) |
|---|---|
| GrabCut + FCN | 49.1 |
| LazySnapping + FCN | 53.8 |
| ours, w/o pairwise terms | 60.5 |
| ours, w/ pairwise terms | 63.1 |
所以说不要听风就是雨, 可以看出分两步走的方案是一个错误的道路, mIoU显著低于 ScribbleSup. 其中的原因主要是这些传统的方法仅仅针对 low-level 的空间或者是色彩信息建模, 并没有考虑到语义的层面. 也就是说, 这些方法得到的 mask 是不值得信赖的, 不能作为 ground truth 来用.
而 ScribbleSup 就不同了, 通过不断的迭代, FCN 能够逐渐学习到 high-level 的语义特征, 这些特征又能反哺给 graph-based scribble propagation. 这样就形成了一个良性循环, 自然 mIoU 就不知比传统方法高到哪里去了.
同时可以看出, 用了成对项的效果比不用的好. 这是因为如果没有了成对项, 那么目标函数就只剩下了一元项, graph cut 步骤变成了基于network prediction 的 winner-take-all 的模式. 这样的话, 信息的传播就只与全卷积有关, 会过于看重局部一致性, 最终导致准确度降低.
Sensitivities to scribble quality
Scribble quality 是个非常主观的东西, 所以为了研究这个对于准确度的影响, 论文里采用了将原 scribble 放缩为不同长度 (甚至是一个点), 然后实验来观察.

| Length ratio | mIoU (%) |
|---|---|
| 1 | 63.1 |
| 0.8 | 61.8 |
| 0.5 | 58.5 |
| 0.3 | 54.3 |
| 0 (spot) | 51.6 |
可以看出, ScribbleSup 对于 scribble length 还是比较鲁棒的, 甚至到了一个点都还能有不错的准确度.
Comparisons with other weakly-supervised methods
All methods are trained on the PASCAL VOC 2012 training images using VGG-16, except that the annotations are different.
| Method | Annotations | mIoU (%) |
|---|---|---|
| MIL-FCN | image-level | 25.1 |
| WSSL | image-level | 38.2 |
| point supervision | spot | 46.1 |
| WSSL | box | 60.6 |
| BoxSup | box | 62.0 |
| ours | spot | 51.6 |
| ours | scribble | 63.1 |
可以看出
- 虽然 image-level 的标注很容易标, 但是训练出来的结果惨不忍睹.
- 同时, 用 scribble 来标注得到的结果准确度很不错, 并且也是相对比较方便的.
- ScribbleSup 即便是用 spot 标注, 结果的 mIoU 也比 point supervision 高了 5%.
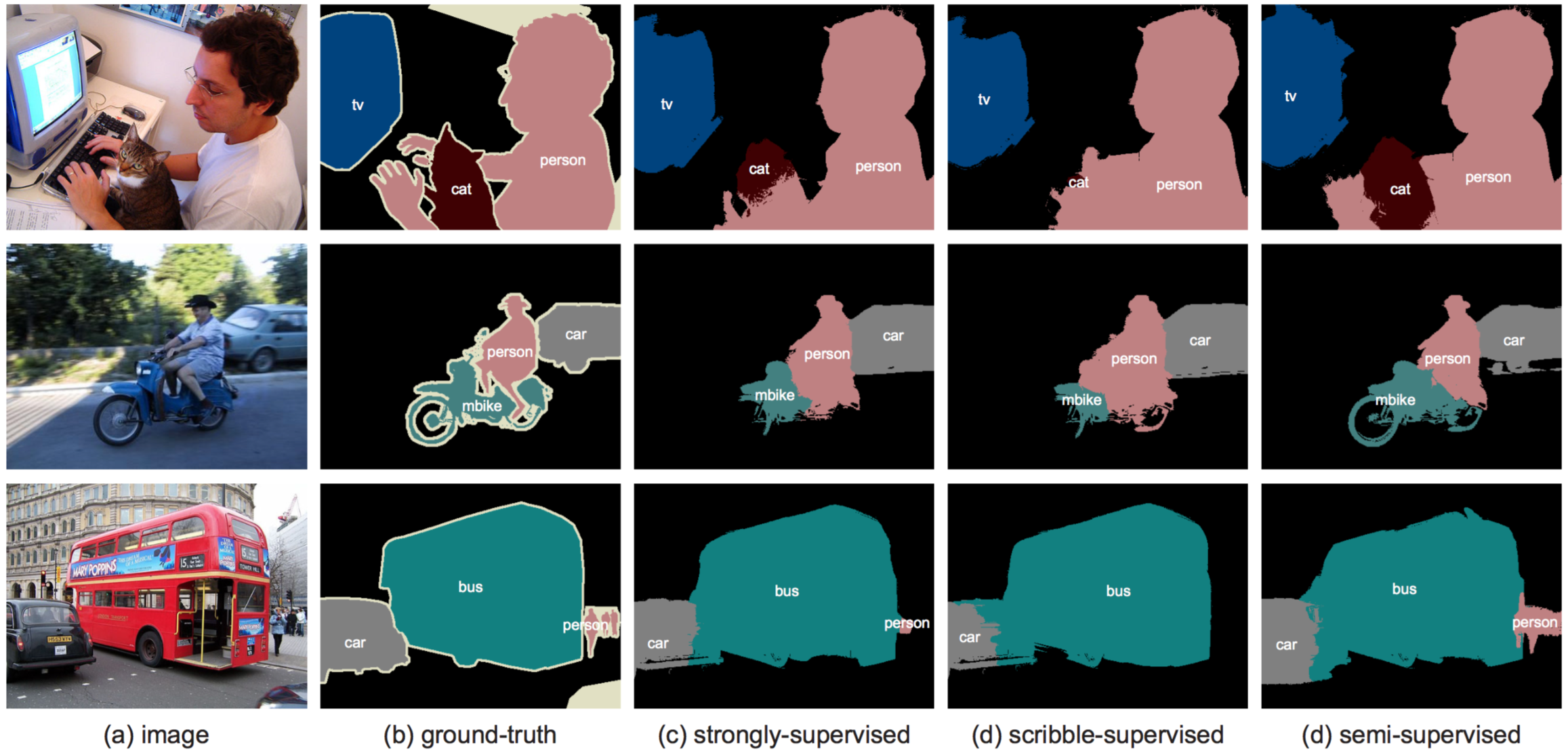
Comparisons with using masks
虐了一遍同等级的 weakly-supervised 的方法之后, ScribbleSup 开始对比使用 scribble 和使用 mask 得到的结果. (在 PASCAL VOC 2012 上训练)
| Supervision | # w/ masks | # w/scribbles | total | mIoU (%) |
|---|---|---|---|---|
| weakly | - | 11k | 11k | 63.1 |
| strongly | 11k | - | 11k | 68.5 |
| semi | 11k | 10k (VOC07) | 21k | 71.3 |
使用 scribble 比使用 mask 得到的结果差了5%左右, 考虑到这两者标注的困难程度, 这点差距还是可以忍的.
ScribbleSup 其实也是可以用 mask-level 的标注来训练的. 对于 mask-level 的标注, 不使用 graph model, 直接扔到 FCN 的训练里面去就行了. 注意的是这些只能用在 FCN 的训练步骤里, 优化 graph model 这一步骤中不使用. 可以看出, scribble 与 mask 联合起来能达到71.3%的 mIoU, 可以说是非常理想了.
Experiments on PASCAL-CONTEXT
To the best of our knowledge, our accuracy is the current state of the art on this dataset. (向dalao低头)
| Method | Data/Annotations | mIoU (%) |
|---|---|---|
| CFM | 5k w/ masks | 34.4 |
| FCN | 5k w/ masks | 35.1 |
| Boxsup | 5k w/ masks + 133k w/ boxes (COCO+VOC7) | 40.5 |
| baseline | 5k w/ masks | 37.7 |
| ours, weakly | 5k w/ scribbles | 36.1 |
| ours, weakly | 5k w/ scribbles + 10k w/ scribbles (VOC07) | 39.3 |
| ours, semi | 5k w/ masks + 10k w/ scribbles (VOC07) | 42.0 |

(To be continued…)